初窥多线程(一) 计算机内存视角下的多线程编程
虚拟地址空间
前言
如果我们比较了解计算机操作系统的话,不难知道操作系统主要有以下四种特征:
- 并发
- 共享
- 虚拟
- 异步
什么是虚拟呢?指的是在计算机操作系统设计时,为了提高对有限空间与时间片的利用,我们一般会选择尝试将一个物理上的实体转换为逻辑上的对应物,我们将这种技术称为虚拟技术,而根据使用目的的不同,我们又将虚拟技术分为两种:时分复用技术与空分复用技术
而什么是空分复用技术呢?空分复用技术又叫虚拟处理器技术,它指的是我们将物理存储器转换为虚拟存储器,在逻辑上扩充存储器的容量。而提到空分复用技术就不能不提到我们今天的要说的虚拟内存地址了。
什么是虚拟内存
虚拟内存的概念比较晦涩难懂,从字面意思来解释的话主要是以下几点:
- 虚拟内存可以用来加载数据,一般是物理内存不够存放的话会放到虚拟内存中
- 虚拟内存所对应的是一段连续的内存地址,起始位置为0(注意:之所以说虚拟,是因为这个起始位置是被虚拟出来的,并不是物理内存的0地址)
虚拟内存的大小一般也是由操作系统所决定的,比如32位操作系统的虚拟地址空间大小为
2^32位,64位操作系统的大小则是2^64位,每当我们在电脑上运行一个可执行程序的时候,就会得到一个进程,内核会给每一个运行的进程创建一块独属于它们的虚拟内存地址空间,并且将应用程序的数据装载到虚拟地址空间对应的地址上。
我们知道进程在运行的时候指令都是由cpu处理完成的,但是我们知道CPU本身是不具有数据存储功能的,数据的取出与存入都是通过物理内存来实现的 ,而这的实现主要就是依托于CPU中的内存管理单元MMU实现物理内存与虚拟内存地址之间的映射。
虚拟内存的意义
那么问题来了,为什么我们不直接使用物理内存而是选择使用虚拟内存地址呢?我们先来看如果将数据直接加载到物理内存中会发生什么:
假设计算机的物理内存大小为1G, 进程A需要100M内存因此直接在物理内存上从0地址开始分配100M, 进程B启动需要250M内存, 因此继续在物理内存上为其分配250M内存, 并且进程A和进程B占用的内存是连续的。之后再启动其他进程继续按照这种方法进行物理内存的分配……
这样做可能会出现以下的问题:
- 应用直接访问物理内存,可能会存在恶意软件通过内存寻址来修改进程的内存数据,哪怕没有恶意程序,可能程序出现了一个Bug就会导致进程的内存数据被修改,不利于数据安全。
- 直接使用内存的话,一个进程所对应的内存是一整块的,如果物理内存不够的话,一般我们会将不常用的进程拷贝到虚拟内存的交换分区,现在就需要直接移动到硬盘了,一方面我们需要将进程一整个移动走,另一方面内存和磁盘之间拷贝时间就会很长,效率低下。
- 物理内存的使用情况一直在动态的变化,我们无法确定内存现在使用到哪里了,如果直接将程序数据加载到物理内存,内存中每次存储数据的起始地址都是不一样的,这样数据的加载都需要使用相对地址,加载效率低。
而我们使用虚拟内存就可以避免上面的问题了,虚拟地址空间就是一个中间层,相当于在程序和物理内存之间设置了一个屏障,将二者隔离开来。程序中访问的内存地址不再是实际的物理内存地址,而是一个虚拟地址,然后由操作系统将这个虚拟地址映射到适当的物理内存地址上。
虚拟内存的分区
从操作系统层面上来说,我们一般会将虚拟内存分为两部分:
- 内核区
- 用户区 这里我们主要介绍一下用户区的组成,用户区的组成主要有九个部分:
env:环境变量,主要是存储与进程相关的环境变量,比如有时候我们导入动态库的时候就需要配置环境变量命令行参数:主要指的是我们代码中main函数的部分参数,也就是argc,argvstack(栈): 存储函数内部声明的非静态局部变量,函数参数,函数返回地址等信息,栈内存由编译器自动分配释放。栈和堆相反地址“向下生长”,分配的内存是连续的。堆(heap):用来存放进程运行时动态分配的内存
- 堆中内容是匿名的,不能按名字直接访问,只能通过指针间接访问。
- 堆向高地址扩展(即“向上生长”),是不连续的内存区域。这是由于系统用链表来 存储空闲内存地址,自然不连续,而链表从低地址向高地址遍历。
.bss段:存储未被初始化的全局变量与静态变量,系统会自动将其初始化为0.data段:存储已经被初始化的全局变量与静态变量,属于静态存储区,可读可写。.text段: 代码段也称正文段或文本段,通常用于存放程序的执行代码(即CPU执行的机器指令),代码段一般情况下是只读的,这是对执行代码的一种保护机制。保留区: 位于虚拟地址空间的最底部,未赋予物理地址。任何对它的引用都是非法的,程序中的空指针(NULL)指向的就是这块内存地址。
线程的概念
线程是一种轻量级的进程,在Linux系统下其实线程的本质还是进程,我们在计算机上运行的程序是一组指令以及指令参数的组合,指令会按照我们所设计的逻辑区执行,操作系统会根据进程为单位来分配系统资源,我们可以这样去理解:线程是操作系统调度执行的最小单位,进程是系统进行资源分配的最小单位。
拓展: 其实除了进程与线程之外还有协程,但是协程并不是相对于操作系统而言的,它由程序员控制调度,本身在运行与使用的过程中是不涉及操作系统内核状态的变化的。
文章的最后我们在来看一下线程与进程之间的区别:
-
进程有自己独立的地址空间,多个线程共用一个地址空间
- 在这个地址空间中每个线程都有自己的栈区与寄存器
- 地址空间中多个线程共享: 代码段, 堆区, 全局数据区, 打开的文件(文件描述符表)
-
线程是程序执行的最小单位,一个地址空间可以划分出多个线程,在充足的资源基础上我们可以抢占更多的
CPU时间片,同时相对于进程,线程上下文切换要更快。 注意:上下文:进/线程复用CPU时间片,在切换之前将上一个任务的状态进行保存,下次切换回这个任务的时候,加载这个状态运行。
初窥多线程(二) 基于C语言实现的多线程编写
前言
在上一篇文章中我们介绍了在计算机底层视角下的虚拟内存和操作系统在用户层所进行的各个分层,在这篇文章我们就要开始尝试书写多线程代码了,其实在c++11后c++就提供供了线程类给我们使用,c++线程类其实主要是对c操作多线程的函数进行了封装,本质上其实是一致的,所以在讲解我们cpp的多线程编写之前,我觉得先来了解一下C语言是如何实现多线程的编写的,这样可以让我们更好的去理解cpp线程类的工作原理,话不多说,发车发车!
线程的创建
在之前我们讲解Linux下的进程控制时说过我们在创建进程时进程都会有自己的进程编号pid,而线程和它们一样,每一个线程都有唯一的线程编号,它的类型为pthread_t,它是一个无符号长整形数,我们可以调用下面这个函数来获取当前线程的线程编号:
pthread_t ptread_self(void); //返回当前线程的线程编号
如果我们希望在一个进程中创建子线程,就要调用线程创建函数,但是和进程不同,我们必须要给每一个线程指定一个线程处理函数,否则线程将无法正常工作,处理函数的定义如下:
int pthread_create(pthread_t *thread, const pthread_attr_t *attr,
void *(*start_routine) (void *), void *arg);
- 参数:
- thread: 传出参数,是无符号长整形数,线程创建成功, 会将线程ID写入到这个指针指向的内存中
- attr: 线程的属性, 一般情况下使用默认属性即可, 写NULL
- start_routine: 函数指针,创建出的子线程的处理动作,也就是该函数在子线程中执行。
- arg: 作为实参传递到 start_routine 指针指向的函数内部
- 返回值:线程创建成功返回0,创建失败返回对应的错误号
下面我们来看一个线程创建的实例:
#include<stdio.h>
#include<stdlib.h>
#include<unistd.h>
#include<string.h>
#include <pthread.h>
// 线程的处理函数
void* work(void* arg)
{
printf("子线程id=%ld\n",pthread_self());
for(int i=0;i<9;i++)
{
printf("child id=%d\n",i);
}
return NULL;
}
int main(int argc,char* argv[])
{
pthread_t tid;
pthread_create(&tid,NULL,work,NULL);
printf("主线程id=%ld\n",pthread_self());
for(int i=0;i<3;i++)
{
printf("main id=%d\n",i);
}
sleep(10);
return 0;
}
注意: 我们在Linux下编译该代码要导入线程库。编译命令如下:
all: demo1
demo1: Create_Thread.c
gcc -pthread -o demo1 Create_Thread.c
clean:
rm -f demo1
运行结果如下:
root@iZuf6ckztbjhtavfplgp0dZ:~/mylib/cppdemo/Linux系统编程/多线程/threads(c)# ./demo1
主线程id=139930484275008
main id=0
main id=1
main id=2
子线程id=139930484270848
child id=0
child id=1
child id=2
child id=3
child id=4
child id=5
child id=6
child id=7
child id=8
如果我们去除sleep函数的使用我们会发现结果是这样的:
主线程id=140150867830592
main id=0
main id=1
main id=2
这是因为虚拟地址生存周期是和主线程保持一致的,与子线程无关,主线程提前结束,导致哪怕子线程还没有开始运行,程序也自动停止运行了,这里的sleep函数所起到的作用主要就是线程同步。
线程的退出
在我们编写多线程代码时,如果我们希望让线程退出,但是不希望因此导致虚拟地址空间的释放(主线程突出时会释放),这时候我们可以调用线程退出函数,这样线程的退出就不会影响其他线程的正常使用了,函数定义如下:
void pthread_exit(void* retval)
- retval:线程退出的时候携带的数据,当前子线程的主线程会得到该数据。如果不需要使用,指定为NULL
下面我们来看一个简单的示例:
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <string.h>
#include <pthread.h>
void* work(void* arg)
{
sleep(5);
printf("子线程运行中,子线程id:%ld\n",pthread_self());\
for(int i=1;i<9;i++)
{
printf("id=:%d\n",i);
if (i==6)
{
pthread_exit(NULL);
}
}
return NULL;
}
int main(int argc,int *argv[])
{
pthread_t tid;
pthread_create(&tid,NULL,work,NULL);
printf("主线程运行中,主线程id:%ld\n",pthread_self());
for(int i=0;i<3;i++)
{
printf("id=:%d\n",i);
}
pthread_exit(NULL);//主线程退出
return 0;
}
输出结果为:
主线程运行中,主线程id:140161600366400
id=:0
id=:1
id=:2
子线程运行中,子线程id:140161600362240
id=:1
id=:2
id=:3
id=:4
id=:5
id=:6
我们可以看到虽然主线程提前推出了,但是却并没有影响到子线程的运行。
线程回收
线程回收函数
进程和线程一样,子线程退出的时候它的内核资源是由主线程来回收,线程回收的函数是pthread_join(),该函数是阻塞函数,当有子线程正在运行,调用该函数会阻塞,直到所有子线程都退出后才能进行子线程资源的回收,一次只能回收一个子线程的资源,如果我们有多个子线程资源需要回收,需要借助循环来完成,函数原型如下:
int pthread_join(pthread_t pid,void** retval);
参数说明:
- pid:要被回收的线程编号
- retval:二级指针,指向一级指针,是一个传出参数 ,一级指针里面储存的是
pthread_exit()函数传出的数据,如果不需要该数据可以设为NULL - 返回值:线程回收成功返回0,回收失败返回错误号。
回收子线程数据的实现方式
在子线程退出的时候可以通过pthread_join函数来将数据传出,我们在回收子线程的同时也可以接收子线程的数据这样的实现方法有很多种,下面我们来看下面几种:
备注:
导致实现方法多样性的原因: 通过上面的介绍,我们知道子线程在被回收的时候会将数据写入到一块内存中,然后采纳数传出该内存的地址而非是存储数据本身,而传出的参数类型是void*,这个万能指针可以指向任意一块内存,也导致了我们可以通过不同的形式来接收子线程数据。
- 使用子线程栈 在我们接收子线程数据的时候可以通过子线程栈来回收子线程数据,示例代码如下:
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <string.h>
#include <pthread.h>
typedef struct Person
{
int id;
char* name;
int age;
}Person;
void* work(void* arg)
{
printf("子线程id:%ld",pthread_self());
for(int i=0;i<9;i++)
{
printf("id=%d\n",i);
if (i==6)
{
Person p;
p.id=1;
p.name="张三";
p.age=20;
pthread_exit((void*)&p);
}
}
return NULL;
}
int main(int argc,char* argv[])
{
pthread_t tid;
if (pthread_create(&tid,NULL,work,NULL)!=0)
{
printf("线程创建失败");
return -1;
}
printf("主线程id:%ld\n",pthread_self());
void *ptr;
pthread_join(tid,&ptr);
struct Person* p=(struct Person*)ptr;
printf("id=%d\n",p->id);
printf("name=%s\n",p->name);
printf("age=%d\n",p->age);
printf("子线程数据成功接收\n");
return 0;
}
我们编译运行后结果如下:
主线程id:139934351951680
子线程id:139934351947520id=0
id=1
id=2
id=3
id=4
id=5
id=6
id=0
name=
age=22476544
子线程数据成功接收
我们可以发现在主线程中并没有子线程的数据,这是因为当子线程退出时,子线程所占据的栈区就会被回收,进而导致了子线程想要传递的数据被释放掉了,所以说我们一般不会采取子线程栈来接收数据,而是使用其他方式来接收数据。 2. 使用全局变量
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <unistd.h>
#include <pthread.h>
typedef struct Person
{
int id;
char* name;
int age;
}Person;
Person p;
void* work(void* arg)
{
printf("子线程id:%ld",pthread_self());
for(int i=0;i<9;i++)
{
printf("id=%d\n",i);
if (i==6)
{
p.id=1;
p.name="张三";
p.age=20;
pthread_exit((void*)&p);
}
}
return NULL;
}
int main(int argc,char* argv[])
{
pthread_t tid;
if (pthread_create(&tid,NULL,work,NULL)!=0)
{
printf("线程创建失败");
return -1;
}
printf("主线程id:%ld\n",pthread_self());
void *ptr;
pthread_join(tid,&ptr);
struct Person* p=(struct Person*)ptr;
printf("id=%d\n",p->id);
printf("name=%s\n",p->name);
printf("age=%d\n",p->age);
printf("子线程数据成功接收\n");
return 0;
}
输出结果为:
主线程id:140702000142144
子线程id:140702000137984id=0
id=1
id=2
id=3
id=4
id=5
id=6
id=1
name=张三
age=20
子线程数据成功接收
- 使用主线程栈 虽然线程之间有自己的栈空间,但是它们彼此之间也可以互相访问,而一般主线程都是最后退出的,所以我们可以尝试把子线程返回的数据保存到了主线程的栈区内存中。
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <unistd.h>
#include <pthread.h>
typedef struct Person
{
int id;
char* name;
int age;
}Person;
void* work(void* arg)
{
Person *p=(Person*)arg;
printf("子线程id:%ld",pthread_self());
for(int i=0;i<9;i++)
{
printf("id=%d\n",i);
if (i==6)
{
p->id=1;
p->name="张三";
p->age=20;
pthread_exit((void*)&p);
}
}
return NULL;
}
int main(int argc,char* argv[])
{
Person p;
pthread_t tid;
if (pthread_create(&tid,NULL,work,&p)!=0)
{
printf("线程创建失败");
return -1;
}
printf("主线程id:%ld\n",pthread_self());
void *ptr;
pthread_join(tid,&ptr);
printf("id=%d\n",p.id);
printf("name=%s\n",p.name);
printf("age=%d\n",p.age);
printf("子线程数据成功接收\n");
return 0;
}
线程分离
在一些情况下,程序中的主线程会拥有自己的业务处理流程,如果让主线程负责子线程的资源回收,那么调用pthread_join函数在子线程全部结束前主线程会一直阻塞,这时候我们可使用线程分离函数来将该线程剥离出来,调用该函数后子线程会与主线程分离,但是这样pthread_join就接收不到子线程资源了,线程分离函数定义如下:
int pthread_detach(pthread_t id);
示例如下:
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <string.h>
#include <pthread.h>
// 子线程的处理代码
void* working(void* arg)
{
printf("我是子线程, 线程ID: %ld\n", pthread_self());
for(int i=0; i<9; ++i)
{
printf("child == i: = %d\n", i);
}
return NULL;
}
int main()
{
//创建一个子线程
pthread_t tid;
pthread_create(&tid, NULL, working, NULL);
printf("子线程创建成功, 线程ID: %ld\n", tid);
// 2. 子线程不会执行下边的代码, 主线程执行
printf("我是主线程, 线程ID: %ld\n", pthread_self());
for(int i=0; i<3; ++i)
{
printf("i = %d\n", i);
}
// 设置子线程和主线程分离
pthread_detach(tid);
// 让主线程自己退出即可
pthread_exit(NULL);
return 0;
}
一些其他的线程函数
线程取消
线程取消指的是我们可以在一个线程中调用它来取消另一个线程,函数定义如下:
int pthread_cancel(pthread_t pid);
代码示例如下:
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <string.h>
#include <pthread.h>
// 子线程的处理代码
void* work(void* arg)
{
printf("我是子线程, 线程ID: %ld\n", pthread_self());
for(int i=0; i<9; ++i)
{
sleep(1);
printf("child == i: = %d\n", i);
}
return NULL;
}
int main()
{
//创建一个子线程
pthread_t tid;
pthread_create(&tid, NULL, work, NULL);
printf("子线程创建成功, 线程ID: %ld\n", tid);
// 2. 子线程不会执行下边的代码, 主线程执行
printf("我是主线程, 线程ID: %ld\n", pthread_self());
for(int i=0; i<3; ++i)
{
sleep(1);
printf("i = %d\n", i);
}
// 设置子线程和主线程分离
pthread_cancel(tid);
// 让主线程自己退出即可
pthread_exit(NULL);
return 0;
}
输出如下:
我是主线程, 线程ID: 139763539765056
我是子线程, 线程ID: 139763539760896
i = 0
child == i: = 0
i = 1
child == i: = 1
i = 2
child == i: = 2
注意:线程的取消分两步:
- 主线程基于线程取消函数发送请求
- 当子线程再次进行系统调用时,线程会被取消(没有这一步,线程就还存在)
结语
关于C语言库中关于线程的函数介绍到此就告一段落了,下一篇文章我们就要开始介绍cpp中一些关于线程的知识了,下篇见!
初窥多线程(三) cpp中的线程类
前言
在cpp11之前其实一直也没有对并发编程有什么语言级别上的支持,而在cpp11中加入了线程以及提供了对线程的封装类,一方面降低了并发编程的难度,另一方面也加强了了多线程程序的可移植性。
线程类(std::thread)
前言
在cpp11中为我们提供了std::thread作为线程类,基于这个类我们可以快速的创建一个新的线程,接下来我们来看一下它的一些常见api:
线程类的构造函数
在我们进行多线程程序的编写时,常见的构造函数主要有以下几种:
thread() noexpect; //普通的构造函数
thread(thread&& other); //移动构造函数
template<class Function,Args... args>
explict thread(Fuction &&f,Args&& ... args); //①
thread(const thread&) =delete; //禁止拷贝构造函数
上面就是主要会使用的多线程构造函数,这里我们主要讲解一下第三个构造函数,其他三个比较好懂,而第三个涉及的cpp11新特性比较多,这里我们着重讲一下:
-
首先是
template<class Function,Args... args>class Function表示的是你想要在线程中执行的函数类型或者是可调用对象的类型,比如普通函数、lambda表达式、函数对象等.Args... args是一个变长模板参数包,表示Function所接受的参数类型序列。...表示可以有任意数量的参数,每个Args代表一个参数类型
-
然后是
explict thread(Fuction &&f,Args&& ... args)explict:explict关键字用于防止隐式类型转换,确保这个构造函数只能被显式调用。这意味着你不能在不需要明确指定类型的情况下意外地创建一个std::thread对象,例如通过自动类型推导或者一些隐式转换操作。thread(Fuction &&f,Args&& ... args):这里函数形参使用右值引用使得左值引用与右值引用都可以绑定在上面,实现了参数的完美转发机制,详细的请参考: cpp随笔——浅谈右值引用,移动语义与完美转发
线程类的公有成员函数
- get_id() 应用程序启动之后默认只有一个线程,这个线程一般称之为主线程或父线程,通过线程类创建出的线程一般称之为子线程,每个被创建出的线程实例都对应一个线程ID,这个ID是唯一的,可以通过这个ID来区分和识别各个已经存在的线程实例,这个获取线程ID的函数叫做get_id(),示例代码如下:
#include <iostream>
#include <thread>
#include <chrono>
using namespace std;
void func(int num, string str)
{
for (int i = 0; i < 10; ++i)
{
cout << "子线程: i = " << i << "num: "
<< num << ", str: " << str << endl;
}
}
void func1()
{
for (int i = 0; i < 10; ++i)
{
cout << "子线程: i = " << i << endl;
}
}
int main()
{
cout << "主线程的线程ID: " << this_thread::get_id() << endl;
thread t(func, 520, "i love you");
thread t1(func1);
cout << "线程t 的线程ID: " << t.get_id() << endl;
cout << "线程t1的线程ID: " << t1.get_id() << endl;
}
这里我们用thread()函数来创建类一个线程,func是线程的工作函数,然后在thread函数中传递工作函数所需的参数。
上述代码存在一个小问题,主线程会在子线程结束前退出,而主线程退出会导致子线程提前退出导致无法得到我们所需的效果。
- join()
这个join的使用基本与c语言中的
pthread_join函数功能相像,我们可以基于这个来修复一下上面代码的bug:
#include <iostream>
#include <thread>
#include <chrono>
using namespace std;
void func(int num, string str)
{
for (int i = 0; i < 10; ++i)
{
cout << "子线程: i = " << i << "num: "
<< num << ", str: " << str << endl;
}
}
void func1()
{
for (int i = 0; i < 10; ++i)
{
cout << "子线程: i = " << i << endl;
}
}
int main()
{
cout << "主线程的线程ID: " << this_thread::get_id() << endl;
thread t(func, 520, "i love you");
thread t1(func1);
cout << "线程t 的线程ID: " << t.get_id() << endl;
cout << "线程t1的线程ID: " << t1.get_id() << endl;
t.join();
t1.join();
return 0;
}
这样就可以得到我们想要的结果了。
- detach() std::thread 类的 detach() 成员函数用于将线程与创建它的线程(即主线程)分离。调用 detach() 后,被分离的子线程将成为一个独立的执行单元,它有自己的生命周期,不再受主线程的控制。
#include <iostream>
#include <thread>
#include <chrono>
using namespace std;
void func(int num)
{
for (int i = 0; i < 10; ++i)
{
cout << "子线程: i = " << i << "num: "
<< num << endl;
}
}
void func1()
{
for (int i = 0; i < 10; ++i)
{
cout << "i = " << i << endl;
}
}
int main()
{
cout << "主线程的线程ID: " << this_thread::get_id() << endl;
thread t(func, 520);
thread t1(func1);
cout << "线程t 的线程ID: " << t.get_id() << endl;
cout << "线程t1的线程ID: " << t1.get_id() << endl;
t.detach();
t1.join();
return 0;
}
注意:
- 线程在被
detach后不能再进行join操作 - 线程对象在销毁前必须选择是
detach或join,否则就会出现异常。
-
joinable()
joinable()函数用于判断主线程和子线程是否处理关联(连接)状态,一般情况下,二者之间的关系处于关联状态,该函数返回一个布尔类型:返回值为true:主线程和子线程之间有关联(连接)关系返回值为false:主线程和子线程之间没有关联(连接)关系 -
operator= 线程的资源是不可复制的,所以我们无法通过重载赋值符获得两个一模一样的线程对象,我们来看一下它的声明:
thread& opreator=(thread&& t)noexcept;
thread& opreator=(thread& t) =delete;
我们可以看到它只进行资源所有权的转移而不进行对对象资源的复制。
静态函数
thread线程类还提供了一个静态方法,用于获取当前计算机的CPU核心数,根据这个结果在程序中创建出数量相等的线程,每个线程独自占有一个CPU核心,这些线程就不用分时复用CPU时间片,此时程序的并发效率是最高的。
int thread::hardware_concurrency();
示例代码:
#include <iostream>
#include <thread>
#include <chrono>
using namespace std;
int main()
{
int num = thread::hardware_concurrency();
cout << num;
return 0;
}
初窥多线程(四) 线程同步与锁
什么是线程同步
线程同步是指多个线程在执行过程中,由于共享资源,导致数据不一致的问题。线程同步是为了解决多个线程同时访问共享资源时,由于线程切换导致的数据不一致问题,大家可能不是很理解为什么要线程同步,我们举个简单的例子:
#include <iostream>
#include <thread>
using namespace std;
int counter=0;
void* ADD_COUNT()
{
for(int i=0;i<100000;i++)
{
counter++;
}
}
int main()
{
thread a(ADD_COUNT);
thread b(ADD_COUNT);
a.join();
b.join();
cout<<"counter="<<counter<<endl;
}
上面代码我这里的运行结果是161335,而不是200000,这就是线程同步的问题,这里我们的counter是共享资源,而a,b两个线程同时访问counter,导致数据不一致,讲的通俗一点,在某个时刻,a和b线程都读到了Count=n,这是它们都会执行count=n+1,然后a线程执行完了,b线程执行完了,最终的结果是n+1,而不是n+2,导致最后的结果小于200000,而为了解决这个问题,我们就需要线程同步,让a,b两个线程不能同时访问共享资源,这样就可以才能保证数据的一致性。
如何实现线程同步
在讲解如何进行线程同步之前,我们要进行线程同步主要是为了防止多个线程同时访问共享资源而造成混乱,所以无论我们采用什么样的手段目的只有一个:保证共享资源在同一时刻只有一个线程访问.
那什么是共享资源呢?所谓的共享资源就是多个线程共同访问的变量,这些变量通常为全局数据区变量或者堆区变量,这些变量对应的共享资源也被称之为临界资源。我们在进行线程同步时所需要做的就是找到这些临界资源,然后保证同一时刻只有一个线程访问这些临界资源.
常见实现线程同步的方法主要有下面几种:
- 锁
- 条件变量
- 信号量
而今天我们介绍的就是——锁.
锁
锁的概念
锁,在我们日常生活中是用来保护我们的私有财产保证其不被他人侵犯,而在计算机中,锁也用来保护资源的,它用来保护共享资源不被多个线程同时访问,保证共享资源在同一时刻只有一个线程访问,从而保证数据的一致性。
互斥锁
互斥锁的原理
互斥锁是一种用于多线程编程中,防止多个线程同时访问共享资源的同步机制。互斥锁可以确保在任何时刻只有一个线程可以访问共享资源,从而避免了数据竞争和一致性问题。它的原理很简单:首先一个共享资源开始是没有锁的,当一个线程想要访问这个共享资源的时候,它会先尝试看这个资源有没有锁,如果没有就可以正常对这个共享资源进行操作,如果有锁,那么这个线程就只能等待,直到锁被释放为止。
互斥锁的种类
cpp11给我们提供了四种互斥锁的类型:
std::mutex mtx; //最简单的互斥锁,不能递归使用
std::recursive_mutex r_mtx; //递归互斥锁
std::timed_mutex t_mtx; //定时互斥锁,可以设置等待时间
std::recursive_timed_mutex rt_mtx; //定时递归互斥锁
我们接下来依次来看看这四种锁的使用方法:
mutex
#include <iostream>
#include <mutex>
#include <chrono>
#include <thread>
using namespace std;
int counter=0;
mutex mtx; //互斥锁
void* ADD_COUNT()
{
for(int i=0;i<100000;i++)
{
mtx.lock(); //加锁,若加锁失败线程会阻塞 除此之外我们还可以加try_lock()尝试加锁,如果加锁失败,则不会阻塞
counter++;
mtx.unlock(); //解锁,若解锁失败,则线程会阻塞
// this_thread::sleep_for(chrono::milliseconds(1)); //休眠1毫秒
}
}
int main()
{
thread a(ADD_COUNT);
thread b(ADD_COUNT);
a.join();
b.join();
cout<<"counter="<<counter<<endl;
}
上面就是一个简单的mutex的例子,我们创建了两个线程,然后让这两个线程去增加一个共享资源,但是这个共享资源被一个互斥锁保护着,所以这两个线程不能同时访问这个共享资源,只能一个一个的来,这样就保证了数据的一致性。而除此之外还有一些其他的函数api:
try_lock尝试加锁,如果加锁失败,则不会阻塞lock加锁,如果加锁失败,则线程会阻塞unlock解锁,如果解锁失败,则线程会阻塞
- timed_mutex
相对于
mutex,timed_mutex多了一个等待时间,如果等待时间到了,还没有加锁成功,那么就会返回false,否则就会返回true,并且会自动解锁
#include <iostream>
#include <mutex>
#include <chrono>
#include <thread>
using namespace std;
chrono::seconds timeout(1); // 超时时间
timed_mutex mtx;
void work()
{
while(true)
{
if(mtx.try_lock_for(timeout))
{
cout<<"线程"<<this_thread::get_id()<<"获取锁"<<endl;
this_thread::sleep_for(chrono::seconds(10));
mtx.unlock();
break;
}
else
{
cout<<"线程"<<this_thread::get_id()<<"正在尝试获取锁......."<<endl;
this_thread::sleep_for(chrono::seconds(1));
}
}
}
int main()
{
thread t1(work);
thread t2(work);
t1.join();
t2.join();
return 0;
}
还有一些其他的api:
try_lock_until尝试加锁,如果加锁失败,则不会阻塞,直到指定的时间点
- recursive_mutex 递归互斥锁std::recursive_mutex允许同一线程多次获得互斥锁,可以用来解决同一线程需要多次获取互斥量时死锁的问题,在下面的例子中使用独占非递归互斥量会发生死锁:
#include <iostream>
#include <mutex>
#include <chrono>
#include <thread>
using namespace std;
class Calculate
{
int m_i;
mutex mtx;
public:
Calculate():m_i(6){}
void mul()
{
mtx.lock();
m_i *= 2;
}
void div()
{
mtx.lock();
m_i /= 2;
}
void test()
{
mul();
div();
}
};
int main()
{
Calculate c;
c.test();
return 0;
}
当我们尝试获取多个锁的时候会出现死锁的情况(什么是死锁我们后面会介绍),所以使用递归锁可以解决这个问题:
#include <iostream>
#include <mutex>
#include <chrono>
#include <thread>
using namespace std;
class Calculate
{
int m_i;
recursive_mutex mtx;
public:
Calculate():m_i(6){}
void mul()
{
mtx.lock();
m_i *= 2;
}
void div()
{
mtx.lock();
m_i /= 2;
}
void test()
{
mul();
div();
show();
}
void show()
{
cout << m_i << endl;
}
};
int main()
{
Calculate c;
c.test();
return 0;
}
- resursive_timed_mutex
这个锁和recursive_mutex类似,但是它提供了超时机制,如果获取锁超时了,就会返回false,否则返回true,这个就不做过多介绍大家可以参考
mutex和timed_mutex的用法。
读写锁
读写锁的介绍
读写锁是一种特殊的互斥锁,我们可以将读写锁看做读锁与写锁,写锁允许多个线程同时读取共享资源,但是只允许一个线程写入共享资源。写锁在写入共享资源时,会阻塞其他线程的读取操作。这样可以保证数据的一致性, 同时避免了多个线程同时同时对共享资源进行不同操作导致的冲突,同时多个线程可以同时读取共享资源,提高了并发性能。
读写锁的实现原理是使用一个计数器来记录当前有多少个线程正在读取/写入共享资源,如果计数器为0,那么就可以写入/读取共享资源,否则就不能写入/读取共享资源。
读写锁的用法
读写锁的常用函数主要有以下几个:
- pthread_rwlock_t rwlock_init(void); // 初始化读写锁
- int pthread_rwlock_destroy(pthread_rwlock_t *rwlock); // 销毁读写锁
- int pthread_rwlock_rdlock(pthread_rwlock_t *rwlock); // 获取读锁
- int pthread_rwlock_wrlock(pthread_rwlock_t *rwlock); // 获取写锁
- int pthread_rwlock_unlock(pthread_rwlock_t *rwlock); // 释放锁
下面是一个简单的读写锁的例子:
#include <iostream>
#include <thread>
#include <vector>
#include <chrono>
#include <random>
#include <pthread.h>
pthread_rwlock_t rwlock;
int count = 0;
std::default_random_engine generator;
std::uniform_int_distribution<int> distribution(0, 4999);
void read(int id) {
pthread_rwlock_rdlock(&rwlock); // 获取读锁
std::cout << "线程 " << id << " 拿到读锁" << std::endl;
std::this_thread::sleep_for(std::chrono::milliseconds(distribution(generator)));
std::cout << "线程 " << id << " 释放读锁" << std::endl;
pthread_rwlock_unlock(&rwlock); // 释放读锁
}
void write(int id) {
pthread_rwlock_wrlock(&rwlock); // 获取写锁
std::cout << "线程 " << id << " 拿到写锁" << std::endl;
int temp = count;
std::this_thread::sleep_for(std::chrono::milliseconds(distribution(generator) % 1000));
count = temp + 1;
std::cout << "线程 " << id << " 释放写锁 " << count << std::endl;
pthread_rwlock_unlock(&rwlock); // 释放写锁
}
void runThreads(int readCount, int writeCount) {
std::vector<std::thread> threads;
for (int i = 0; i < readCount; ++i) {
threads.emplace_back(read, i);
}
for (int i = 0; i < writeCount; ++i) {
threads.emplace_back(write, i + readCount);
}
for (auto& th : threads) {
th.join();
}
}
int main() {
pthread_rwlock_t rwlock;
pthread_rwlock_init(&rwlock, NULL);
const int readCount = 7;
const int writeCount = 3;
runThreads(readCount, writeCount);
std::cout << "最终结果: " << count << std::endl;
pthread_rwlock_destroy(&rwlock);
return 0;
}
lock_guard以及unique_lock
lock_guard
互斥锁的获取和释放必须成对出现,而一旦出现线程在获取互斥锁而没有释放时,其它线程将永远等待!(使用 lock() 的情况下)为了解决此类情况,C++ 标准库提供了一个 RAII 式(什么是RAII我们后面会有所介绍)的方案,即模板类 lock_guard。 该类需要传入一个泛型参数,表示锁的类型,同时该类需要传入一个具体的锁,这样你仅需要初始化一个 lock_guard, 线程将自动获取锁,同时在线程结束时,临时变量被销毁,同时锁也会被释放。
#include <iostream>
#include <mutex>
#include <thread>
using namespace std;
int a = 1;
mutex a_mutex;
void increase() {
lock_guard<mutex> lg(a_mutex);
this_thread::sleep_for(2000ms);
++a;
}
int main() {
thread t1(increase);
thread t2(increase);
t1.join();
t2.join();
cout << a << endl; // 3
return 0;
}
unique_lock
上面我们已经介绍了lock_guard,lock_guard 虽然方便,却仍有其不便之处,那就是锁的粒度太大了,在 lock_guard 中,上锁发现在初始化过程,而释放锁则需要在对象被销毁时,这样显然是不够灵活的。所以这里我们要介绍一个更灵活的模板类 unique_lock,它允许我们自定义锁的粒度,同时它还支持 RAII 的特性,即锁的获取和释放。
它具有下面这些特性:
- 延迟锁定(deferred locking)
- 尝试锁定 (attempts at locking)
- 超时机制 (time-constrained)
- 递归锁定 (recursive locking)
- 转移互斥锁的所有权 (transfer of lock ownership)
- 与条件变量一起使用 (use with condition variables)
不过unique_lock只是一个灵活的锁管理器,它并不能直接对互斥锁进行上锁和解锁操作,它需要与互斥锁配合使用,对锁进行包装,接下来我们来看一下他是怎么实现它的这些特性的:
- 延迟锁定
void increase() {
unique_lock<mutex> ul(a_mutex, defer_lock); // 延迟锁定,初始化时并不上锁,需要我们手动上锁
this_thread::sleep_for(2000ms);
ul.lock(); // 手动上锁
++a;
}
- 尝试锁定
void increase() {
unique_lock<mutex> ul(a_mutex, try_to_lock); // 尝试锁定,如果锁已经被其他线程占用,则返回false,否则返回true
if(!ul.owns_lock()) {
this_thread::sleep_for(2000ms);
cout<<"failed to get mutex"
}
++a;
}
- 超时机制
void increase() {
unique_lock<timed_mutex> ul(a_mutex, defer_lock);
if(!ul.try_lock_for(2s)) {
cout<<"timeout";<<endl;
}
++a;
}
- 递归锁定
void once() {
unique_lock<recursive_mutex> ul(m);
++shared;
cout << "once\n";
}
void twice() {
unique_lock<recursive_mutex> ul(m);
for (int i = 0; i < 2; i++) {
cout << "twice: ";
once();
}
}
- 移交所有权
void func() {
unique_lock ul(m);
unique_lock ul2 = move(ul); // 移动构造,此时锁的所有权已经转移给ul2
ul2.swap(ul); // 交换所有权,结束后ul有锁,ul2不再拥有锁
ul.release(); // 释放所有权,此时ul不再拥有锁
++a;
m.unlock(); // unlock the m mutex manually
}
shared_mutex
shared_mutex 是 C++17 引入的新的互斥锁类型,它允许多个线程同时拥有读权限,但只有一个线程可以拥有写权限。shared_mutex 提供了以下功能:
- lock():获取独占锁,阻塞直到成功获取锁。
- try_lock():尝试获取独占锁,如果失败则立即返回 false。
- unlock():释放独占锁。
- lock_shared():获取共享锁,阻塞直到成功获取锁。
- try_lock_shared():尝试获取共享锁,如果失败则立即返回 false。
- unlock_shared():释放共享锁。
这里我们就不得不说一下什么是独占锁和共享锁了
和我们日常生活的独占与共享一样,独占锁就是只能一个线程访问,而共享锁就是多个线程可以访问,当我们读取的时候,可以多个线程同时读取,但是写入的时候,只能有一个线程写入,其他线程需要等待写入完成才能继续写入。在读多写少的场景下,shared_mutex 可以提高并发性能。
示例:
#include <iostream>
#include <thread>
#include <mutex>
#include <shared_mutex>
using namespace std;
int a = 1;
shared_mutex sm;
int read() {
shared_lock<shared_mutex> sl(sm);
cout << "read\n";
this_thread::sleep_for(2s);
return a;
}
int main() {
thread t1(read);
thread t2(read);
thread t3(read);
thread t4(read);
t1.join();
t2.join();
t3.join();
t4.join();
return 0;
}
大家可以尝试运行一下代码,会发现2szuong 4 个线程同时读取了 a 的值,而不是是按照顺序读取的。
死锁问题
死锁的产生原因
死锁的原因在于两个线程同时获取多个锁且存在获取的锁被对方占用的时候,这个时候线程将永远处于阻塞状态,比如下面这样:
#include <iostream>
#include <mutex>
#include <thread>
using namespace std;
int a = 1, b = 1;
mutex a_mutex, b_mutex;
void increase1() {
lock_guard<mutex> lg1(a_mutex);
this_thread::sleep_for(1000ms);
++a;
lock_guard<mutex> lg2(b_mutex);
++b;
}
void increase2() {
lock_guard<mutex> lg1(b_mutex);
this_thread::sleep_for(1000ms);
++b;
lock_guard<mutex> lg2(a_mutex);
++a;
}
int main() {
thread t1(increase1);
thread t2(increase2);
t1.join();
t2.join();
cout << a << endl << b;
return 0;
}
在上面的代码中t1在获取完a锁,t2在获取完b锁之后,t1需要获取b锁,t2需要获取a锁,但是a锁和b锁都被对方占用,导致两个线程都处于阻塞状态,程序将永远无法结束,而这也就是我们所说的死锁了。
预防死锁的方法
-
避免多次锁定, 多检查
-
对共享资源访问完毕之后, 一定要解锁,或者在加锁的使用 trylock
-
如果程序中有多把锁, 可以控制对锁的访问顺序(顺序访问共享资源,但在有些情况下是做不到的),另外也可以在对其他互斥锁做加锁操作之前,先释放当前线程拥有的互斥锁。
-
项目程序中可以引入一些专门用于死锁检测的模块
参考文章与链接
条件变量与信号量
条件变量
什么是条件变量
条件变量是线程间同步的一种机制,它允许一个或多个线程在某些条件满足时被唤醒,从而继续执行。条件变量通常与互斥锁一起使用,以确保线程在访问共享资源时不会发生竞争条件,常见的条件变量主要有以下几种:
- condition-variable:提供与 std::unique_lock关联的条件变量
- condition_variable_any:提供与任何锁类型关联的条件变量
两者的主要区别在于,condition_variable_any可以凭借unique_lock来与任何类型的锁一起使用,而condition_variable只能与std::mutex一起使用。
条件变量的基本操作
条件变量的操作主要包括两个:
- wait:等待条件变量,直到条件满足
- notify_one/notify_all:通知等待条件变量的线程
关于这两个操作的常见api主要有下面几种:
- wait:等待条件变量,直到条件满足
- wait_for:等待条件变量,直到条件满足或超时
- wait_until:等待条件变量,直到条件满足或指定的时间点
- notify_one:通知一个等待条件变量的线程
- notify_all:通知所有等待条件变量的线程
基于条件变量的生产者消费者模型
下面我们来看一下如何使用上面所说的条件变量来实现一个生产者消费者模型(考虑到两个条件变量的用法基本一致,我们只以condition_variable为例):
//test.h
#include <iostream>
#include <condition_variable>
#include <thread>
#include <chrono>
#include <mutex>
#include <list>
#include <functional>
using namespace std;
#define MAX_SIZE 100 // 任务队列的最大长度
template <typename T>
class SyncQueue
{
private:
mutex m_mutex; // 互斥锁
condition_variable non_empty; // 判断当前生产者消费者模型中的任务队列是否为空
condition_variable non_full; // 判断当前生产者消费者模型中的任务队列是否为满
list<T> m_queue; // 任务队列
int m_maxsize; // 任务队列的最大长度
public:
SyncQueue() : m_maxsize(MAX_SIZE) {} // 构造函数
void put(T t) // 生产函数
{
unique_lock<mutex> lock(m_mutex); // 这里通过unique_lock来获取互斥锁,保证线程安全
non_full.wait(lock, [this]()
{ return m_queue.size() != m_maxsize; }); // 等待任务队列不满
m_queue.push_back(t);
cout << t << " 被生产" << endl;
non_empty.notify_one(); // 唤醒一个消费者线程
}
T take() // 消费函数
{
unique_lock<mutex> lock(m_mutex); // 这里通过unique_lock来获取互斥锁,保证线程安全
non_empty.wait(lock, [this]()
{ return m_queue.size() > 0; }); // 等待任务队列不为空
T t = m_queue.front();
m_queue.pop_front();
non_full.notify_one(); // 唤醒一个生产者线程
cout << t << " 被消费" << endl;
return t;
}
bool empty()
{
unique_lock<mutex> locker(m_mutex);
return m_queue.empty();
}
bool full()
{
unique_lock<mutex> locker(m_mutex);
return m_queue.size() == m_maxsize;
}
int size()
{
unique_lock<mutex> locker(m_mutex);
return m_queue.size();
}
~SyncQueue() {} // 析构函数
};
//test1.cpp
#include "./include/test.h"
int main()
{
SyncQueue<int> q;
auto produce=std::bind(&SyncQueue<int>::put,&q,std::placeholders::_1);
auto consume=std::bind(&SyncQueue<int>::take,&q);
thread t1[3],t2[3];
for(int i=0;i<3;i++)
{
t1[i]=thread(produce,i+100);
t2[i]=thread(consume);
}
for(int i=0;i<3;i++)
{
t1[i].join();
t2[i].join();
}
return 0;
}
同时附上cmake文件(仅供参考):
# 设置打印编译信息
set(CMAKE_VERBOSE_MAKEFILE ON)
# 设置cmake编译器最低版本
cmake_minimum_required (VERSION 3.10)
project (learn_thread)
#头文件搜素路径
include_directories(${PROJECT_SOURCE_DIR}/include)
# 添加可执行文件
add_executable(demo1 test1.cpp)
# 添加链接库
link_libraries(demo1 PRIVATE Threads::Threads)
# 添加编译选项
add_compile_options(-c -g)
信号量
在多进程编程中我们就对信号量做了一定的介绍,在cpp20中,并发库对信号量做了封装实现,让我们对信号量有更方便的操作。
信号量的种类
cpp11中信号量分为两种,一种为计数信号量,一种为二值信号量。
- 计数信号量:计数信号量可以用于控制多个线程对共享资源的访问,当计数信号量大于0时,线程可以访问共享资源,当计数信号量等于0时,线程需要等待信号量释放。
- 二值信号量:二值信号量只能用于控制两个线程对共享资源的访问,当二值信号量等于1时,线程可以访问共享资源,当二值信号量等于0时,线程需要等待信号量释放。
其实本质上来说,二值信号量实现的是一个类似于互斥量的功能,但是二值信号量起到的更多的是一个信号的作用,他是通知线程之间的事件,比如线程是应该执行还是阻塞,而互斥量起到的更多的是一个锁的作用,他是保护共享资源不被多个线程同时访问。
而计数信号量则可以用于控制多个线程对共享资源的访问,当计数信号量大于0时,线程可以访问共享资源,当计数信号量等于0时,线程需要等待信号量释放。
信号量的api
虽然信号量的之类有二值和计数两种,但是他们的api都是一样的,只是初始化的参数不同,首先我们来看一下它们共有的api;
- release():释放信号量,将信号量的计数加1。
- acquire():获取信号量,将信号量的计数减1,如果计数小于0,则线程需要等待信号量释放。
- try_acquire():尝试获取信号量,将信号量的计数减1,如果计数小于0,则返回false,否则返回true。
- try_acquire_for():尝试获取信号量,将信号量的计数减1,如果计数小于0,则等待一段时间,如果等待时间到了,则返回false,否则返回true。
- try_acquire_until():尝试获取信号量,将信号量的计数减1,如果计数小于0,则等待直到指定的时间,如果等待时间到了,则返回false,否则返回true。
信号量的初始化
信号量的初始化有两种方式,一种是通过构造函数,一种是通过赋值操作符。
- 构造函数:构造函数需要传入一个整数,表示信号量的初始计数。
信号量的使用
首先是binary_semaphore,我们将演示如何使用binary_semaphore来控制两个线程对共享资源的访问。
#include <iostream>
#include <thread>
#include <semaphore>
#include <chrono>
#include <mutex>
#include <random>
std::binary_semaphore binary_lock(1); // 初始状态为有信号
int count=0; // 共享变量
void add()
{
for(int i=0;i<100000;i++)
{
binary_lock.acquire(); // 获取信号量,如果信号量为0,则阻塞当前线程(信号量的P操作)
count++;
binary_lock.release(); // 释放信号量,将信号量加1(信号量的V操作);
}
}
int main()
{
std::thread t1(add);
std::thread t2(add);
t1.join();
t2.join();
std::cout<<"count="<<count<<std::endl;
return 0;
}
然后是count_semaphore,我们将演示如何用它配合std::mutex来控制对共享资源的访问,这里我们以生产者消费者模型为例:
#include <iostream>
#include <queue>
#include <thread>
#include <chrono>
#include <mutex>
#include <condition_variable>
#include <random>
const int BUFFER_SIZE = 10;
std::queue<int> buffer;
std::mutex buffer_mutex;
std::condition_variable cond_var;
bool stop_threads = false;
// 生产者和消费者的逻辑保持不变,但是需要监听stop_threads标志。
void producer(int id) {
int count = 0;
std::random_device rd;
std::mt19937 gen(rd());
std::uniform_int_distribution<> dis(1000, 5000);
while (!stop_threads) {
std::unique_lock<std::mutex> lk(buffer_mutex);
cond_var.wait(lk, [] { return buffer.size() < BUFFER_SIZE; }); // 等待缓冲区非满
buffer.push(count);
std::cout << "Produced: " << count << std::endl;
count++;
lk.unlock();
cond_var.notify_one(); // 通知消费者
std::this_thread::sleep_for(std::chrono::milliseconds(dis(gen)));
}
}
void consumer(int id) {
//定义随机数生成器
std::random_device rd;
std::mt19937 gen(rd());
std::uniform_int_distribution<> dis(1000, 5000);
while (!stop_threads) {
std::unique_lock<std::mutex> lk(buffer_mutex);
cond_var.wait(lk, [] { return !buffer.empty(); }); // 等待缓冲区非空
int value = buffer.front();
buffer.pop();
std::cout << "Consumed: " << value << std::endl;
lk.unlock();
cond_var.notify_one(); // 通知生产者
std::this_thread::sleep_for(std::chrono::milliseconds(dis(gen))); // 模拟消费时间
}
}
int main() {
std::thread prod(producer, 0);
std::thread cons(consumer, 0);
prod.join();
cons.join();
// 设置停止标志并唤醒所有等待中的线程
stop_threads = true;
cond_var.notify_all();
return 0;
}
备注:
- 由于上面的有关信号量的信号量封装类是cpp20的产物,所以我们编译的时候药品注意编译器版本,编译命令可以参考:
g++ -std=c++20 -o test test2.cpp
- 在信号量的初始化函数中其实STL标准库中只有
std::counting_semaphore<LeastMaxValue>::counting_semaphore
在源码中关于binary_semaphore的初始化函数是这样的:
using binary_semaphore = std::counting_semaphore<1>;
所以两种信号量本质上用法没有什么太大区别,只不过binary_semaphore是count_semphore的一个特例,我们在使用时
std::binary_semaphore binary_lock(1);
也不过是初始化二值信号量的状态。
基于多线程实现的并发服务器
//server
#include <iostream>
#include <cstring>
#include <thread>
#include <unistd.h>
#include <sys/types.h>
#include <sys/socket.h>
#include <netinet/in.h>
#include <arpa/inet.h>
using namespace std;
struct SockInfo {
int fd; // 通信句柄
pthread_t pid; // 线程id
sockaddr_in addr; // 客户端地址
};
SockInfo sock_infos[128];
sockaddr_in server_addr;
int listenfd;
bool InitServer(unsigned int port, unsigned int backlog) { // backlog为单个线程的最大连接数
listenfd = socket(AF_INET, SOCK_STREAM, 0); // 初始化服务端的监听
if (listenfd < 0) {
perror("listensocket init failed");
return false;
}
memset(&server_addr, 0, sizeof(server_addr));
server_addr.sin_family = AF_INET;
server_addr.sin_port = htons(port);
server_addr.sin_addr.s_addr = htonl(INADDR_ANY); // 监听所有网卡
int ret = bind(listenfd, (struct sockaddr*)&server_addr, sizeof(server_addr)); // 绑定
if (ret < 0) {
perror("bind failed");
return false;
}
ret = listen(listenfd, backlog);
if (ret < 0) {
perror("listen failed");
return false;
}
return true;
}
void* worker(void* arg) {
SockInfo* pinfo = (SockInfo*)arg;
cout<<"child thread, connfd: " << pinfo->fd << endl;
while (true) {
char buff[1024];
memset(buff, 0, sizeof(buff));
int ret = recv(pinfo->fd, buff, sizeof(buff), 0);
if (ret == 0) {
cout << "client disconnected" << endl;
pinfo->fd = -1;
break;
} else if (ret == -1) {
perror("recv failed");
break;
}
cout << "receive msg: " << buff << endl;
ret=send(pinfo->fd,buff,strlen(buff),0);
if(ret==-1)
{
perror("send failed");
return 0;
}
cout<<"send msg: "<<buff<<endl;
}
close(pinfo->fd);
pthread_exit(NULL);
}
int main(int argc, char* argv[]) {
if (argc < 2) {
cerr << "Usage: " << argv[0] << " <port>" << endl;
return EXIT_FAILURE;
}
unsigned int port = atoi(argv[1]);
if (!InitServer(port, 5)) {
exit(EXIT_FAILURE);
}
int max = sizeof(sock_infos) / sizeof(sock_infos[0]);
for (int i = 0; i < max; i++) {
memset(&sock_infos[i], 0, sizeof(sock_infos[i]));
sock_infos[i].fd = -1;
sock_infos[i].pid = -1;
}
SockInfo* pinfo;
while (true) {
// 创建子线程
int found = 0;
for (int i = 0; i < max; i++) {
if (sock_infos[i].fd == -1) {
pinfo = &sock_infos[i];
found = 1;
break;
}
}
if (!found) { // 如果没有找到空闲位置
// 拒绝新的连接请求
int connfd = accept(listenfd, (struct sockaddr*)&pinfo->addr, (socklen_t*)&(pinfo->addr));
if (connfd != -1) {
char error_msg[] = "已达到连接数的最大值\n";
send(connfd, error_msg, sizeof(error_msg) - 1, 0); // 发送错误信息
close(connfd); // 关闭连接
continue;
}
}
int connfd = accept(listenfd, (struct sockaddr*)&pinfo->addr, (socklen_t*)&(pinfo->addr));
if (connfd == -1) {
perror("accept failed");
continue;
}
pinfo->fd = connfd;
cout << "parent thread, connfd: " << connfd << endl;
// 创建线程处理客户端连接
pthread_create(&pinfo->pid, NULL, worker, pinfo);
pthread_detach(pinfo->pid); // 设置线程为分离状态
}
close(listenfd);
return 0;
}
// client
#include <iostream>
#include <cstring>
#include <cstdio>
#include <unistd.h>
#include <netdb.h>
#include <sys/socket.h>
#include <sys/types.h>
using namespace std;
int main(int argc,char *argv[])
{
if(argc!=3)
{
cout<<"Examples: ./demo1 服务端 端口号"<<endl;
return -1;
}
//创建socket套接字
int socketid=socket(AF_INET,SOCK_STREAM,0);
if(socketid==-1)
{
perror("socket error");
return -1;
}
//绑定服务端
struct hostent* h; //存放服务端IP的数据结构
if((h=gethostbyname(argv[1]))==0)
{
perror("gethostbyname error");
close(socketid);
return -1;
}
struct sockaddr_in serveraddr;
memset(&serveraddr,0,sizeof(serveraddr));
serveraddr.sin_family=AF_INET;
serveraddr.sin_port=htons(atoi(argv[2]));
if(connect(socketid,(struct sockaddr*)&serveraddr,sizeof(serveraddr))==-1)
{
perror("connect error");
close(socketid);
return -1;
}
//通讯
int iret;
char buffer[1024];
memset(buffer,0,sizeof(buffer));
for(int i=1;i<10;i++)
{
//发送报文
sprintf(buffer,"这是第%d份报文",i);
if((iret=send(socketid,buffer,strlen(buffer),0))==-1)
{
perror("send error");
close(socketid);
break;
}
sleep(10);
cout<<"发送成功"<<endl;
//接收回应报文
memset(buffer,0,sizeof(buffer));
if((iret=recv(socketid,buffer,sizeof(buffer),0))==-1)
{
perror("recv error");
close(socketid);
break;
}
cout<<"接收成功"<<endl;
}
//断开连接,释放资源
close(socketid);
cout<<"连接已断开"<<endl;
return 0;
}
```
RAII与智能指针
前言
在前面的章节中,我们介绍了多线程编程中的基本概念,包括线程的创建、同步、互斥等。在锁的介绍那篇文章中我们介绍了锁的包装器unique_lock与lock_guard,它们都是基于RAII(Resource Acquisition Is Initialization)原则的智能指针。RAII是一种编程范式,它使用对象的生命周期来管理资源的分配和释放。在多线程编程中,RAII可以有效地避免资源泄露和死锁等问题。而这篇文章我们将从RAII开始,探究c++11后内存管理的一些新特性.
RAII
RAII(Resource Acquisition Is Initialization)是一种编程原则,它要求在创建对象时自动分配资源,并在对象销毁时自动释放资源。RAII通过将资源分配和释放封装在构造函数和析构函数中,实现了资源的自动管理,从而避免了手动管理资源带来的errors和bugs。RAII的核心思想是:将资源的分配和释放与对象的生命周期绑定在一起,当对象被创建时,资源被分配;当对象被销毁时,资源被释放。这种机制可以有效地避免资源泄露和死锁等问题。
在RAII一般是不会轻易使用浅拷贝的,因为浅拷贝会带来资源泄露的问题。例如,如果两个对象共享同一个资源,并且其中一个对象被销毁,那么另一个对象将无法访问该资源,从而导致资源泄露。因此,在RAII中,通常会使用深拷贝来避免资源泄露的问题。我们用下面的一个简单例子来说明一下:
#include <iostream>
using namespace std;
class RAII
{
private:
int* ptr;
public:
RAII():ptr(new int(10)){}
~RAII(){delete ptr;}
};
int main()
{
RAII r1;
RAII r2(r1); // 拷贝构造函数
return 0;
}
上面的代码中我们定义了一个简单的RAII类,并且示例化了两个对象r1和r2,但是当我们运行这段代码时,会出现一个错误,如果说在运行中我们不小心释放了r1的资源,由于r1与r2张建是浅拷贝的关系,它们使用的本质上是同一块内存,我们释放了r1的内存,r2的内存也就被释放了,这会导致程序崩溃。为了解决这个问题,我们可以下面的方法:
- 使用深拷贝来避免资源泄露的问题,但是频繁的复制会造成不必要的资源浪费。
- 使用引用计数来管理资源的共享。
而如何应用计数来管理资源的共享呢?这就需要我们引入智能指针了。
智能指针
智能指针是一种自动管理内存的机制,它通过引用计数来管理资源的共享。智能指针在对象被创建时自动分配资源,并在对象被销毁时自动释放资源。智能指针通过引用计数来跟踪对象的引用次数,当引用次数为0时,智能指针会自动释放资源。智能指针可以避免手动管理内存带来的errors和bugs,并且可以有效地避免资源泄露和死锁等问题。常见的智能指针主要有下面四种:
std::auto_ptr:自动指针,在C++11中已弃用。std::shared_ptr:共享指针,允许多个智能指针共享同一个对象,当最后一个智能指针被销毁时,对象才会被销毁。std::unique_ptr:独占指针,独占一个对象,当智能指针被销毁时,对象才会被销毁。std::weak_ptr:弱指针,不拥有对象的所有权,可以用来解决循环引用的问题。
在对智能指针 讲解之前微妙先看几个智能指针中比较主要的api:
- reset:释放当前管理的资源,并将指针置为空。
- release:释放当前管理的资源,但是不将指针置为空。
- swap:交换两个智能指针管理的资源。
- get:返回当前管理的资源的指针。
- use_count:返回当前管理的资源的引用计数。
- expire:返回当前管理的资源是否已经被释放。
下面我们依次来看一下这几个智能指针的使用:
- std::auto_ptr:自动指针,在C++11中已弃用。
auto_ptr作为智能指针弊端是最明显的,它采用的所有权转移方法是隐式转移所有权,我们可以来看一下它的相关实现:
class auto_ptr{
auto_ptr& operator=(auto_ptr tmp) noexcept {
// copy and swap技术,这里不展开了
// 注意当拷贝构造函数构造tmp时,会发生所有权的转移
tmp.swap(*this);
return *this;
}
// 拷贝构造,被复制时释放原来指针的所有权,交给复制方
auto_ptr(auto_ptr &other) noexcept {
ptr_ = other.release();
}
// 原来的指针释放所有权
T *release() noexcept {
T *ptr = ptr_;
ptr_ = nullptr;
return ptr;
}
};
在新的指针获取了旧指针资源后,旧指针就被置为空指针了,这时候我们再去访问旧指针就会造成未定义行为,所以auto_ptr在C++11中就被弃用了。
- std::shared_ptr:共享指针,允许多个智能指针共享同一个对象,当最后一个智能指针被销毁时,对象才会被销毁。
在介绍shared_ptr之前,我写一个简易版的shared_ptr,来帮助大家理解shared_ptr的实现原理:
#include <iostream>
#include <memory>
#include <utility>
#include <atomic>
using namespace std;
template<typename T>
class Shared_ptr {
private:
using element_type = T;
element_type* ptr; ////智能指针管理的指针/资源
atomic<int>* count; //引用计数
public:
Shared_ptr() : ptr(nullptr), count(nullptr) {} //默认构造函数
explicit Shared_ptr(T* ptr) : ptr(ptr), count(new atomic<int>(1)) {} //避免智能指针被用于隐式类型转换或复制初始化
Shared_ptr(const Shared_ptr& rhs) : ptr(rhs.ptr), count(rhs.count) { ////拷贝构造函数
if (*count) ++(*count);
}
Shared_ptr& operator=(const Shared_ptr<T>& rhs) { //拷贝赋值运算符
if (this != &rhs) {
Shared_ptr tmp(rhs);
swap(tmp);
}
return *this;
}
Shared_ptr(Shared_ptr&& rhs) noexcept : ptr(rhs.ptr), count(rhs.count) { //移动构造函数
rhs.ptr = nullptr;
rhs.count = nullptr;
}
Shared_ptr& operator=(Shared_ptr<T>&& rhs) noexcept { //移动赋值运算符
if (this != &rhs) {
Shared_ptr tmp(std::move(rhs));
swap(tmp);
}
return *this;
}
~Shared_ptr() { //析构函数
if (ptr != nullptr) {
--(*count);
if (*count == 0) {
delete ptr;
delete count;
}
}
}
void swap(Shared_ptr& rhs) { //交换两个智能指针
std::swap(ptr, rhs.ptr);
std::swap(count, rhs.count);
}
void reset(T* ptr = nullptr) { //将当前Shared_ptr 置为空,并释放其所管理的对象。
Shared_ptr tmp(ptr);
swap(tmp);
}
element_type* get() const noexcept { //返回原始指针(即 T*)
return ptr;
}
int use_count() const noexcept { //返回当前有多少个Shared_ptr 对象指向同一个对象
return *count;
}
bool unique() const noexcept { //返回当前Shared_ptr是否是唯一的
return *count == 1;
}
element_type& operator*() const noexcept { //
return *ptr;
}
element_type* operator->() const noexcept { //返回指针指向的对象
return ptr;
}
explicit operator bool() const noexcept { //返回当前指针是否为空
return ptr != nullptr;
}
};
template<typename T, typename... Args>
Shared_ptr<T> make_Shared(Args&&... args) {
T* ptr = new T(std::forward<Args>(args)...);
atomic<int>* count = new atomic<int>(1);
return Shared_ptr<T>(ptr);
}
我们不难看到在Shared_ptr中,主要有两个变量,一个是原始指针ptr,另一个是引用计数count。ptr指向实际管理的对象,而count则记录有多少个Shared_ptr指向同一个对象。当创建一个Shared_ptr对象时,引用计数会加1,当Shared_ptr对象被销毁时,引用计数会减1,当引用计数为0时,则说明没有Shared_ptr指向该对象,此时就会释放该对象。理解了这个,在结合一下上面的代码基本就理解了shared_ptr的原理了。
- std::unique_ptr:独占式智能指针,它不允许其他的智能指针共享其内部的指针,不允许通过复制构造函数或赋值操作符复制。它通过在析构函数中删除指针来实现自动释放内存的功能。
还是和原先一样我们来看一个手写的简单unique_ptr:
#ifndef UNIQUE_PTR_H
#define UNIQUE_PTR_H
#include <iostream>
#include <memory>
#include <type_traits>
using namespace std;
template<typename T, typename Deleter = std::default_delete<T>>
class Unique_Ptr {
private:
T* ptr; //指向被管理的对象的指针
Deleter deleter; //自定义删除器
public:
Unique_Ptr() : ptr(nullptr), deleter() {} //默认构造函数
explicit Unique_Ptr(T* ptr, Deleter d = Deleter()) : ptr(ptr), deleter(std::move(d)) {} //普通构造函数
Unique_Ptr(const Unique_Ptr<T, Deleter>&) = delete; //禁止拷贝构造函数
Unique_Ptr& operator=(const Unique_Ptr<T, Deleter>&) = delete; //禁止赋值操作符
Unique_Ptr(Unique_Ptr<T, Deleter>&& other) : ptr(other.ptr), deleter(std::move(other.deleter)) { //移动构造函数
other.ptr = nullptr;
}
Unique_Ptr& operator=(Unique_Ptr<T, Deleter>&& other) { //移动赋值操作符
if (this != &other) {
deleter(this->ptr);
ptr = other.ptr;
deleter = std::move(other.deleter);
other.ptr = nullptr;
}
return *this;
}
void swap(Unique_Ptr<T, Deleter>& other) noexcept { //交换指针
std::swap(ptr, other.ptr);
std::swap(deleter, other.deleter);
}
T* get() const { //返回指向被管理对象的指针
return ptr;
}
Deleter get_deleter() const { //返回删除器
return deleter;
}
T* release() { //释放被管理对象的所有权
T* temp = ptr;
ptr = nullptr;
return temp;
}
void reset(T* new_ptr = nullptr) { //释放被管理对象的所有权并指向新的对象
if (ptr != nullptr) {
deleter(ptr);
}
ptr = new_ptr;
}
T& operator*() const { //解引用操作符
return *ptr;
}
T* operator->() const { //箭头操作符
return ptr;
}
explicit operator bool() const noexcept { //显式转换为布尔值
return ptr != nullptr;
}
~Unique_Ptr() { //析构函数
if (ptr != nullptr) {
deleter(ptr);
}
}
};
#endif // UNIQUE_PTR_H
unique_ptr在cpp11中被提出,用来替换我们上面所说弊端很大的auto_ptr,我们可以看到在我们的实现中它并不支持拷贝构造函数和赋值操作符,这样我们就避免了auto_ptr中出现的隐藏bug,并且它还支持自定义删除器deleter,这样我们就可以在释放内存的时候执行一些额外的操作,比如释放资源等,而翻译删除器的方式也很简单:
struct CustomDeleter 、
{
void operator()(int* p) const
{
std::cout << "Deleting with custom deleter" << std::endl;
delete p;
}
};
Unique_Ptr<int, CustomDeleter> uptr_custom(new int(30), CustomDeleter())
;
自定义删除器的方式不仅仅是unique_ptr,shared_ptr中也可以实现自定义删除器来用来关闭一些资源,比如文件,数据库连接等。
unique_ptr与shared_ptr最大的区别就在于unique_ptr拥有对象的所有权,而shared_ptr则共享对象的所有权,unique_ptr在释放对象的时候会直接释放内存,而shared_ptr则会通过引用计数来管理对象的生命周期,当引用计数为0的时候才会释放内存。
- std::weak_ptr
std::weak_ptr是一种不控制所指向对象生存期的智能指针,它指向一个std::shared_ptr管理的对象。std::weak_ptr不会改变引用计数,它的构造不会增加引用计数,析构也不会减少引用计数。std::weak_ptr可以用来解决std::shared_ptr循环引用的问题。
weak_ptr也有主要有下面几个api:
std::weak_ptr<T> wptr; //创建一个空的weak_ptr
std::weak_ptr<T> wptr(sp); //使用shared_ptr创建一个weak_ptr
wptr.reset(); //将wptr置空
wptr.expired(); //检查所管理的对象是否已经释放,返回true表示已经释放
,返回false表示未释放
wptr.lock(); //如果weak_ptr管理的对象还存在,则返回一个shared_ptr,否则返回一个空的shared_ptr
这里我们主要介绍lock和expire函数以及std::shared_ptr和std::weak_ptr的循环引用问题。
首先是lock和expire函数,lock函数会返回一个std::shared_ptr,如果weak_ptr管理的对象还存在,则返回一个std::shared_ptr,否则返回一个空的std::shared_ptr,expire函数则会检查weak_ptr管理的对象是否还存在(就是我们查看指向的shared_ptr计数器的值是否大于0,大于就是存在,小于就是不存在),如果存在则返回false,否则返回true。
然后就是std::shared_ptr和std::weak_ptr的循环引用问题,循环引用问题会导致内存泄漏,因为std::shared_ptr和std::weak_ptr都会增加引用计数,当引用计数为0的时候才会释放内存,如果两个std::shared_ptr互相引用对方,那么引用计数永远不会为0,就会导致内存泄漏。
我们来看下面的一个例子:
#include <iostream>
#include <memory>
using namespace std;
class Parent;
class Child;
typedef shared_ptr<Parent> parent_ptr;
typedef shared_ptr<Child> child_ptr;
class Parent
{
public:
~Parent() {
cout << "~Parent()" << endl;
}
public:
child_ptr children;
};
class Child
{
public:
~Child() {
cout << "~Child()" << endl;
}
public:
parent_ptr parent;
};
int main()
{
parent_ptr father(new Parent);
child_ptr son(new Child);
// 父子互相引用
father->children = son;
son->parent = father;
cout << father.use_count() << endl; // 引用计数为2
cout << son.use_count() << endl; // 引用计数为2
return 0;
}
上面的代码中,Parent和Child互相引用对方,导致引用计数永远不会为0,从而导致了内存泄漏。我们可以使用std::weak_ptr来解决这个问题,std::weak_ptr不会增加引用计数,所以不会导致循环引用问题。
#include <iostream>
#include <memory>
using namespace std;
class Parent;
class Child;
typedef shared_ptr<Parent> parent_ptr;
typedef shared_ptr<Child> child_ptr;
class Parent
{
public:
~Parent() {
cout << "~Parent()" << endl;
}
public:
weak_ptr<Child> children;
};
class Child
{
public:
~Child() {
cout << "~Child()" << endl;
}
public:
weak_ptr<Parent> parent;
};
int main()
{
parent_ptr father(new Parent);
child_ptr son(new Child);
// 父子互相引用
father->children = son;
son->parent = father;
cout << father.use_count() << endl;
cout << son.use_count() << endl;
return 0;
}
在上面的代码中,我们使用了std::weak_ptr来代替std::shared_ptr,这样就不会导致循环引用问题。当Parent和Child对象被销毁时,它们的析构函数会被调用,输出~Parent()和~Child(),表示对象被正确地销毁了。
什么是池化技术
池化技术是一种资源管理策略,它通过重复利用已存在的资源来减少资源的消耗,从而提高系统的性能和效率。在计算机编程中,池化技术通常用于管理线程、连接、数据库连接等资源。
我们会将可能使用的资源预先创建好,并且将它们创建在一个池中,当需要使用这些资源时,直接从池中获取,使用完毕后再将它们归还到池中,而不是每次都创建和销毁资源。
池化技术的引用场景十分广泛,例如线程池、数据库连接池、对象池等,今天我们主要要探讨的就是线程池
什么是线程池
线程池是一种典型的池化技术的应用,在我们日常使用多线程来处理任务时,如果每次都创建和销毁线程,频繁的创建与销毁线程会出现大量不必要的资源消耗,降低系统的性能。而在线程池中我们可以预先创建一定数量的线程,当需要执行任务时,直接从线程池中获取线程来执行任务,任务执行完毕后,线程并不会被销毁,而是继续保留在线程池中,等待下一次任务的执行,通过这种线程复用的方式,可以大大减少线程的创建和销毁,从而提高系统的性能和效率。
线程池的优点
-
避免频繁创建与销毁线程:线程池预先创建并维护一定数量的工作线程,避免了频繁创建和销毁线程带来的系统开销,特别是在处理大量短生命周期任务时,效果尤为显著。
-
负载均衡与缓存局部性:线程池可以根据任务负载动态调整线程工作状态,避免过度竞争和闲置。同时,线程在执行任务过程中可以充分利用CPU缓存,提高执行效率。
-
控制并发级别:通过限制线程池大小和任务队列容量,可以有效控制系统的并发级别,防止因过度并发导致的资源争抢和性能下降。
-
简化编程模型
-
线程池提供了一种简化的编程模型,开发者无需关心线程的创建、管理和销毁,只需将任务提交给线程池即可。这大大简化了多线程编程的复杂性,提高了开发效率。
-
线程池还提供了一些高级功能,如任务优先级、任务超时、任务取消等,这些功能可以帮助开发者更好地管理任务执行过程,提高系统的可靠性和稳定性。
-
线程池的组成部分
该线程池类的主要有以下组成部分
-
线程池类 线程池类主要负责管理线程池的状态并根据线程池的状态淘汰的管理工作线程的状态并且实现任务的异步提交
- 工作线程类
- 有关线程池状态的枚举类
- 任务队列
task_queue - 用来存放工作线程的列表
worker_list - 控制线程池状态/工作线程列表/以及任务队列的互斥锁
- 用于唤醒/阻塞线程的条件变量
- 基于线程异步实现的任务提交函数 相关定义如下:
class ThreadPool { private: class worker_thread; // 工作线程类 enum class status_t : std::int8_t { TERMINATED = -1, TERMINATING = 0, RUNNING = 1, PAUSED = 2, SHUTDOWN = 3 }; // 线程池的状态: 已终止:-1,正在终止:0,正在运行:1,已暂停:2,等待线程池中任务完成,但是不接收新任务:3 std::atomic<status_t> status; // 线程池的状态 std::atomic<std::size_t> max_task_count; // 线程池中任务的最大数量 std::shared_mutex status_mutex; // 线程池状态互斥锁 std::shared_mutex task_queue_mutex; // 任务队列的互斥锁 std::shared_mutex worker_lists_mutex; // 工作线程列表的互斥锁 std::condition_variable_any task_queue_cv; // 任务队列的条件变量 std::condition_variable_any task_queue_cv_full; // 任务队列满的条件变量 std::condition_variable_any task_queue_cv_empty; // 任务队列空的条件变量 std::queue<std::function<void()>> task_queue; // 任务队列,其中存储待执行的任务 std::list<worker_thread> worker_lists; // 工作线程列表 // 考虑到为了确保线程池的唯一性和安全性,禁止使用拷贝赋值与移动赋值 ThreadPool(ThreadPool &) = delete; ThreadPool &operator=(ThreadPool &) = delete; ThreadPool(ThreadPool &&) = delete; ThreadPool &operator=(ThreadPool &&) = delete; // 在取得对状态变量的访问权后,调用下列函数来改变线程池的状态 void pause_with_status_lock(); // 暂停线程池 void resume_with_status_lock(); // 恢复线程池 void shutdown_with_status_lock(); // 立刻关闭线程池 void shutdown_with_wait_status_lock(bool wait_for_tasks); // 等待任务执行完毕关闭线程池 void terminate_with_status_lock(); // 终止线程池 void wait_with_status_lock(); // 等待所有任务执行完毕 public: ThreadPool(std::size_t max_task_count,std::size_t inital_thread_count=0); // 构造函数 ~ThreadPool(); // 析构函数 template <typename Func, typename... Args> auto submit(Func &&f, Args &&...args) -> std::future<decltype(f(args...))>; // 提交任务,实现对线程任务的异步提交 void pause(); // 暂停线程池 void resume(); // 恢复线程池 void shutdown(); // 立刻关闭线程池 void shutdown_wait(); // 等待任务执行完毕关闭线程池 void terminate(); // 终止线程池 void wait(); // 等待所有任务执行完毕 void add_thread(std::size_t count); // 增加线程 void remove_thread(std::size_t count); // 删除线程 void set_max_task_count(std::size_t count); std::size_t get_task_count(); // 获取任务数量 std::size_t get_thread_count(); // 获取线程数量 }; template <typename Func, typename... Args> auto ThreadPool::submit(Func &&f, Args &&...args) -> std::future<decltype(f(args...))> { std::shared_lock<std::shared_mutex> status_lock(status_mutex); switch (status.load()) { case status_t::TERMINATED: throw std::runtime_error("ThreadPool is terminated"); case status_t::TERMINATING: throw std::runtime_error("ThreadPool is terminating"); case status_t::PAUSED: throw std::runtime_error("ThreadPool is paused"); case status_t::SHUTDOWN: throw std::runtime_error("ThreadPool is shutdown"); case status_t::RUNNING: break; } if(max_task_count > 0&&max_task_count.load()==get_task_count()) throw std::runtime_error("ThreadPool is full"); using return_type=decltype(f(args...)); auto task=std::make_shared<std::packaged_task<return_type()>>(std::bind(std::forward<Func>(f), std::forward<Args>(args)...)); std::unique_lock<std::shared_mutex> lock2(task_queue_mutex); task_queue.emplace([task](){ (*task)(); }); lock2.unlock(); status_lock.unlock(); task_queue_cv.notify_one(); //唤醒一个线程来执行当前任务 std::future<return_type> res=task->get_future(); return res; } -
工作线程类 工作线程类主要负责从任务队列中取出任务并执行,同时处理根据当前自身线程的状态变化动态调整线程池的状态。
- 有关工作线程状态的枚举类
- 线程状态的原子变量
- 控制线程阻塞/唤醒的condition_variable 相关定义如下:
class ThreadPool::worker_thread { private: enum class status_t:int8_t{ TERMINATED=-1, TERMINATING=0, PAUSE=1, RUNNING=2, BLOCKED=3 }; // 1- 线程已终止 0- 线程正在终止 1- 线程已暂停 2- 线程正在运行 3- 线程已阻塞,等待任务中 ThreadPool *pool; //指向线程池 std::atomic<status_t> status; //线程状态 std::shared_mutex status_mutex; //线程状态互斥锁 std::binary_semaphore sem; //信号量,要来控制线程的阻塞和唤醒 std::thread thread; //工作线程 //禁用拷贝构造与移动构造以及相关复赋值 worker_thread(const worker_thread &) = delete; worker_thread(worker_thread &&) = delete; worker_thread &operator=(const worker_thread &) = delete; worker_thread &operator=(worker_thread &&) = delete; void resume_with_status_lock(); status_t terminate_with_status_lock(); void pause_with_status_lock(); public: worker_thread(ThreadPool *pool); ~worker_thread(); void pause(); void resume(); status_t terminate(); };
线程池的工作机理剖析
对于该项目的线程池而言,它主要存在下面三个机制:
- 基于状态机的状态转换
- 任务的异步执行机制
- 工作线程的任务执行
- 基于状态机的状态转换
在线程池中主要有两种状态转换,首先是线程池的状态转换,这里我们通过枚举定义了线程池的不同状态,让线程池在这些状态中不断切换,枚举类的定义如下:
enum class status_t : std::int8_t
{
TERMINATED = -1,
TERMINATING = 0,
RUNNING = 1,
PAUSED = 2,
SHUTDOWN = 3
};
// 线程池的状态: 已终止:-1,正在终止:0,正在运行:1,已暂停:2,等待线程池中任务完成,但是不接收新任务:3
std::atomic<status_t> status;//线程池的状态,这里使用原子变量来保证操作的原子性,实现了线程安全
而线程池的状态机模型如下:

具体的状态转化代码可以参考:
void ThreadPool::pause_with_status_lock()
{
switch (status.load())
{
case status_t::TERMINATED: // 线程池已经终止
case status_t::TERMINATING: // 线程池正在终止
case status_t::PAUSED: // 线程池已经暂停
case status_t::SHUTDOWN: // 线程池已经关闭
return;
case status_t::RUNNING:
status.store(status_t::PAUSED);
break;
default:
throw std::runtime_error("unknown status");
}
std::unique_lock<std::shared_mutex> lock(worker_lists_mutex);
for (auto &worker : worker_lists)
{
worker.pause();
}
}
工作线程的状态转换就简单了,只有四种状态:
enum class status_t:int8_t{
TERMINATED=-1,
TERMINATING=0,
PAUSE=1,
RUNNING=2,
BLOCKED=3
}; // 1- 线程已终止 0- 线程正在终止 1- 线程已暂停 2- 线程正在运行 3- 线程已阻塞,等待任务中
它的状态转换基本上和线程池息息相关,可以参考线程池的状态转换,这里不做过多说明。
- 任务的异步执行
在讲线程的异步执行之前,先来了解一下什么是线程的异步执行:
在计算机科学中,“异步”通常指的是一个操作在发起之后,不需要等待其完成就可以继续执行后续的操作。异步编程模型允许程序在等待某个耗时操作完成的同时继续执行其他任务,从而提高整体效率和响应速度。
在c++11中为了实现异步执行,引入了std::async,它可以在一个单独的线程中执行一个函数,并返回一个std::future对象,通过这个对象可以获取函数的返回值。这里不做赘述,后面我们单独出一篇文章来探讨这个问题,这里我们只需要知道它的作用就可以了。这里我们来看一下线程池的任务提交函数submit:
template <typename Func, typename... Args>
auto ThreadPool::submit(Func &&f, Args &&...args) -> std::future<decltype(f(args...))>
{
std::shared_lock<std::shared_mutex> status_lock(status_mutex);
switch (status.load())
{
case status_t::TERMINATED:
throw std::runtime_error("ThreadPool is terminated");
case status_t::TERMINATING:
throw std::runtime_error("ThreadPool is terminating");
case status_t::PAUSED:
throw std::runtime_error("ThreadPool is paused");
case status_t::SHUTDOWN:
throw std::runtime_error("ThreadPool is shutdown");
case status_t::RUNNING:
break;
}
if(max_task_count > 0&&max_task_count.load()==get_task_count())
throw std::runtime_error("ThreadPool is full");
using return_type=decltype(f(args...));
auto task=std::make_shared<std::packaged_task<return_type()>>(std::bind(std::forward<Func>(f), std::forward<Args>(args)...));
std::unique_lock<std::shared_mutex> lock2(task_queue_mutex);
task_queue.emplace([task](){ (*task)(); });
lock2.unlock();
status_lock.unlock();
task_queue_cv.notify_one(); //唤醒一个线程来执行当前任务
std::future<return_type> res=task->get_future();
return res;
}
它的实现思路如下:
- 首先查看当前线程池的状态,如果不是RUNNING状态,抛出异常
- 查看当前的任务队列是否已满,如果已满,则抛出异常
- 将任务转换为std::packaged_task对象,并将其包装为std::function对象,以便在线程池中执行,这里使用了std::forward将参数传递给任务函数实现完美转发,通过std::function对象将任务函数包装std::function<void()>类型,以便在线程池中通过在工作线程中可以用统一的格式(直接用 () 进行调用)对任何形式的任务进行调用执行。
- 将std::packaged_task对象添加到任务队列中,并返回一个std::future对象,该对象可以用于获取任务函数的返回值
- 工作线程的任务执行
在讲解工作线程的任务执行之前,我们先来看一下它的具体实现:
ThreadPool::worker_thread::worker_thread(ThreadPool *pool):pool(pool),status(status_t::RUNNING),sem(0),thread(
[this](){
while (true)
{
// 实现线程状态的判断,决定是否由该线程执行任务
std::unique_lock<std::shared_mutex> unique_lock_status(this->status_mutex);
while (true)
{
if (!unique_lock_status.owns_lock()) // 当锁被释放时,重新获取锁
{
unique_lock_status.lock();
}
bool break_flag = false; // 当线程为运行态的时候,跳出循环
switch (this->status.load())
{
case status_t::TERMINATING:
this->status.store(status_t::TERMINATED);
case status_t::TERMINATED:
return;
case status_t::RUNNING:
break_flag = true;
break;
case status_t::PAUSE: // PAUSE状态下需要其他的线程来唤醒该线程需要解锁避免出现死锁
unique_lock_status.unlock();
this->sem.acquire(); // 阻塞当前线程
break;
case status_t::BLOCKED: // 不支持Blocked
default:
unique_lock_status.unlock();
throw std::runtime_error("invalid status");
}
if (break_flag)
{
unique_lock_status.unlock();
break;
}
}
// 判断队列是否为空,如果为空则阻塞当前线程
std::unique_lock<std::shared_mutex> unique_lock_task(this->pool->task_queue_mutex);
while (this->pool->task_queue.empty())
{
while (true)
{
if (!unique_lock_status.owns_lock())
{
unique_lock_status.lock();
}
bool break_flag = false;
switch (this->status.load())
{
case status_t::TERMINATING:
status.store(status_t::TERMINATED);
case status_t::TERMINATED:
return;
case status_t::PAUSE:
unique_lock_task.unlock();
unique_lock_status.unlock();
this->sem.acquire(); // 阻塞线程
break;
case status_t::RUNNING:
this->status.store(status_t::BLOCKED);
case status_t::BLOCKED:
break_flag = true;
break;
default:
unique_lock_status.unlock();
unique_lock_task.unlock();
throw std::runtime_error("invalid status");
}
if (break_flag) // 若为阻塞状态等待唤醒
{
unique_lock_status.unlock();
break;
}
}
this->pool->task_queue_cv.wait(unique_lock_task);
while (true)
{
if (!unique_lock_status.owns_lock())
{
unique_lock_status.lock();
}
bool break_flag = false;
switch (this->status.load())
{
case status_t::TERMINATING:
status.store(status_t::TERMINATED);
case status_t::TERMINATED:
return;
case status_t::PAUSE:
unique_lock_task.unlock();
unique_lock_status.unlock();
this->sem.acquire(); // 阻塞线程
break;
case status_t::BLOCKED:
this->status.store(status_t::RUNNING);
case status_t::RUNNING:
break_flag = true;
break;
default:
unique_lock_status.unlock();
throw std::runtime_error("invalid status");
}
if (break_flag) // 若为阻塞状态等待唤醒
{
unique_lock_status.unlock();
break;
}
}
}
// 尝试取出任务并执行
try
{
auto task = this->pool->task_queue.front();
this->pool->task_queue.pop();
if (this->pool->task_queue.empty())
{
this->pool->task_queue_cv_empty.notify_all();
}
unique_lock_task.unlock();
task();
}
catch (const std::exception &e)
{
std::cerr<<e.what()<<std::endl;
}
}
}){}
工作线程工作的进行是定义在线程构造函数中,即线程开始工作后,会一直执行这个函数,直到线程被销毁,它的实现逻辑是:
- 确定工作线程状态,决定是否由该线程执行任务
- 查看工作队列是否为空,不为空则取出一个任务
- 执行任务
- 根据线程池状态变更,如接收到暂停、恢复、终止等指令,工作线程调整自身状态并执行相应操作
拓展:ini文件的读写
考虑到线程池后续想要对其进行拓展,例如加入epoll进行网络通信,所以我实现了一个简单的ini解析器,他主要有两部分:
- Value类:实现了
int,double,long,string等基础类型与Value对象之间的互相转换,代码如下:
class Value // 封装一个Value对象,支持string、int、double、bool类型,可以实现多个类型转换为Value对象,并且可以转换为多个类型
{
private:
std::string m_value;
public:
//支持各个类型的构造函数
Value();
Value(const std::string& value);
Value(const int value);
Value(const double value);
Value(const bool value);
Value(const char* value);
~Value();
//赋值操作,支持任意类型
Value& operator=(const std::string& value);
Value& operator=(const int value);
Value& operator=(const double value);
Value& operator=(const bool value);
Value& operator=(const char* value);
//对于值的判断
bool operator==(const Value& other);
bool operator!=(const Value& other);
//这里实现可以将Value对象转换为任意类型
operator int();
operator double();
operator bool();
operator std::string();
};
- IniFile:基于嵌套map来存储ini文件的各个分区与分区的键值对,实现如下:
typedef std::map<std::string, Value> Section;
class IniFile
{
private:
std::string m_filename;
std::map<std::string, Section> m_sections;
std::string trim(std::string s); //去除字符串两边的空格
public:
IniFile();
IniFile(const std::string& filename);
~IniFile();
bool load(const std::string& filename); //加载ini文件
bool save(const std::string& filename); //保存ini文件
void show(); //显示ini文件内容
void clear(); //清空ini文件内容
Value& get(const std::string& section,const std::string& key); //获取指定分区指定键的值
void set(const std::string& section,const std::string& key,const Value& value); //设置指定分区指定键的值
bool remove(const std::string& section,const std::string& key); //删除指定分区指定键的值
bool has(const std::string& section,const std::string& key); //判断键值对是否存在
bool has(const std::string& section);// 判断分区是否存在
Section& operator[](const std::string& section); // 重载[]操作符,用来访问分区中的键值
std::string str(); //将字符串转换为ini文件格式
};
篇幅有限,就不粘详细代码了,大家也可以尝试自己实现以下,毕竟cpp就是一个不断遭轮子的过程。
结语
线程池的实现是一个复杂的过程,需要考虑多线程并发、任务调度、线程管理等多个方面。本文通过一个简单的线程池实现,介绍了线程池的基本原理和实现方法。希望本文对您有所帮助。
linux的信号
信号的概念
在Linux中,信号是一种用于进程间通信和处理异步事件的机制,用于进程之间相互传递消息和通知进程发生了事件,但是,它不能给进程传递任何数据。
信号产生的原因有很多种,在shell中,我们可以使用kill和killall来发送信号
kill -信号的类型 进程编号
killall -信号的类型 进程名
信号的类型
常见信号类型:
SIGINT:终止进程(键盘快捷键ctrl+c)SIGKILL: 采用kill -9 进程编号,强制杀死程序
......
信号的处理
进程对信号的处理方法一般有三种:
- 对该信号进行默认处理,一般是终止该进程
- 设置中断的处理函数,受到该型号的函数进行处理
- 忽略该信号,不做如何处理
signal()函数可以设置程序对信号的处理方式
函数的声明:
sighandler_t signal(int signum,sighandler_t handler)
注释:
参数signum表示信号的编号
参数handler表示信号的处理方式,有三种情况:
SIG_DFL:恢复参数signum所指信号的处理方法为默认值- 一个自定义的处理信号的函数,信号的编号为这个自定义函数的参数
SIG_IGN:忽略signum所指的信号
示例代码:
#include <iostream>
#include <unistd.h>
#include <signal.h>
using namespace std;
void func(int signum)
{
cout<<"收到了信号"<<signum<<endl;
signal(1,SIG_DFL);//将函数的处理方式由自定义函数改为了默认方式处理
}
int main(int argc,char *argv[],char *envp[])
{
signal(1,func);
signal(15,func);
signal(2,SIG_IGN);//忽略信号2
while(1)
{
cout<<argc<<endl;
sleep(1);
}
return 0;
}
信号的作用
服务程序运行在后台,如果想终止它,一般不会直接杀死它,以防止出现意外。
我们·一般会选择向进程去发送一个信号,当程序收到这个信号的时候能够调用函数,并通过函数中英语善后的代码,原计划的退出。
我们也可以向其发送0的信号来确保程序是否存活
示例代码:
#include <iostream>
#include <signal.h>
using namespace std;
void Exit(int signum)
{
cout<<"收到了"<<signum<<"信号"<<endl;
cout<<"开始释放资源并退出"<<endl;
//释放资源的代码
cout<<"退出程序"<<endl;
exit(0);
}
int main()
{
for(int i=1;i<=64;i++)
{
signal(i,SIG_IGN);
}
signal(2,Exit);
signal(15,Exit);
while(1)
{
cout<<"fengxu\n";
}
}
进程终止
进程的终止
在main()函数中,return的返回值就是终止状态,如果没有return语句或者调用exit(),那么该进程终止状态为0
我们可以通过
echo $?
来查看线程终止的状态
正常终止进程函数有三个:
void exit(int status);
void _exit(int status);
void _Exit(int status);
status也是进程终止的状态
注意:进程如果被异常终止,终止状态也为非0
资源释放
return表示函数返回,会调用局部对象的析构函数,main()函数中的return还会调用全局对象的析构函数
exit()表示进程终止,它不会调用局部对象的析构函数,只会调用全局变量的析构函数
注意:exit()会执行清理工作再退出,但是_EXIT()和——exit()不会执行清理工作
进程的终止函数
进程可以利用atexit函数来登记终止函数(最多32个),这些函数将由exit()自动调用。
**注意:**运行登记函数的顺序与登记函数顺序相反
示例代码:
#include <iostream>
#include <stdlib.h>
using namespace std;
void fuc1()
{
cout<<"调用了fuc1()"<<endl;
}
void fuc2()
{
cout<<"调用了fuc2()"<<endl;
}
int main()
{
atexit(fuc1);
atexit(fuc2);
exit(0);
}
输出:

进程的创建
整个Linux系统全部的进程是一个树状结构
0号进程(系统进程):所有进程的祖先,创建了1号进程与2号进程
1号进程(systemd):负责执行内核的初始化工作与继续系统配置
2号进程(kthreadd):负责所有内核线程的调度与管理
我们可以使用pstree命令来查看进程树,命令为:
pstree -p 进程编号
示例:
进程标识
每一个进程的有一个非负整数标识的唯一的进程ID,虽然是唯一,但是我们可以复用进程ID,当一个进程终止以后,该进程ID自然就成为了复用的候选者,但Linux本身采用的是延迟服用算法,让新建进程的ID不同于最近计数进程的ID,防止被误以为进程尚未终止
pid_t getpid(void) //获取当前进程的ID
pid_t getppid(void) //获取父进程的ID
说明:
pid_t:非负整数
fork函数
fork 函数的使用
一个现有的进程能够调用fork()函数去创建一个新的进程
pid_t fork(void);
由fork()创建的进程叫做子进程,下面演示一个例子:
//demo1.cpp
#include <iostream>
#include<unistd.h>
using namespace std;
int main()
{
fork();
cout<<"hello world"<<endl;
sleep(100);
cout<<"over";
return 0;
}
我们可以使用命令来查看一下它的进程
ps -ef |grep demo1

我们用上面的查看进程树命令来试一下:
pstree -p 214251

我们可以看到它创建了一个子进程
分割子进程与父进程
fork()会返回值,而子进程与父进程的返回值不同,示例代码如下:
#include <iostream>
#include <unistd.h>
using namespace std;
int main()
{
fork();
int pid=fork();
cout<<pid<<endl;
}
输出结果:

我们可以发现:
子进程的返回值:0
父进程的返回值:父进程的进程ID
所以我们可以通过这个来选择父进程与子进程所执行的代码
示例代码:
#include <iostream>
#include <unistd.h>
using namespace std;
int main()
{
int pid = fork();
if(pid==0) cout<<"现在执行的是子进程"<<endl;
if(pid>0) cout<<"现在执行的是父进程"<<endl;
}
输出结果:

子进程与父进程之间的关系
在子进程被创建之后,它与父进程之间并不是共享堆栈以及数据空间的而是子进程获得了父进程的数据空间以及堆栈的副本
fork()的两种用法
- 父进程复制自己,然后父进程与子进程分别执行不同的代码,多见于网络服务程序,父进程等待客户端的连接请求,当请求到达的时候,父进程调用
fork(),让子进程处理请求,而父进程等待下一个连接请求 - 进程需要执行另一个程序,这种多见于shell中,让子进程去执行exec族函数
共享文件
fork()的一个特性是在父进程中打开的文件描述符都会被复制到子进程中,父进程与子进程共享一个文件偏移量(子进程所写的内容会在父进程所写内容的后面)
注意:如果父进程与子进程写同一描述符指向的文件,但是每一然后显示的同步,那么它们的输出可能相互混合
vfork()函数
vfork()函数的调用与fork函数相同,但两者的语义不同
vfork()函数用于创建一个新进程,而新进程的目的是exec一个新程序,由于我们要求子进程必须立即执行,所以它不复制父进程的地址空间
vfork()与fork()的另一个区别:vfork()保证子进程先执行,保证了子进程调用exec函数或exit()之后父进程才恢复执行.
僵尸进程
前言
如果父进程比子进程先退出,子进程将被1号进程所托管(这是一种让进程在后台运行的方法),而如果子进程比父进程先退出,且父进程并没有处理子进程退出的信息的话,那么子进程将成为僵尸进程.
代码示例:
#include <iostream>
#include <unistd.h>
using namespace std;
int main()
{
if(fork()==0) return 0;
for(int i=0;i<1000;i++)
{
cout<<"hello world"<<endl;
sleep(100);
}
return 0;
}


我们可以看到哪怕子进程已经退出了,但是我们查找进程的时候,子进程依旧存在,这时候它就成为了一个僵尸进程。
僵尸进程的危害
Linux内核给每一个子进程都保留了一个数据结构,它包括了进程编号,终止状态,使用cpu时间等等。当父进程处理了子进程的退出之后内核会将这个数据结构释放掉,而父进程如果没有将子进程的退出处理掉,内核就不会释放这个数据结构,这样会导致子进程的基础编号一直被占用,而进程编号的数量是有限的,这样将影响系统去创建新的进程
如何避免僵尸进程
-
子进程退出的时候,内核需要向父进程发出
SIGCHLD信号,如果父进程用signal(SIGCHLD,SIG_INT)来表示对子进程的退出不做处理,内核将自动释放子进程的数据结构 -
父进程通过
wait/waitpid函数等待子进程结束,子进程退出前,父进程将被阻塞pid_t wait(int *stat_loc); pid_t waitpid(pid_t pid, int *stat_loc, int options); pid_t wait3(int *stat_loc, int options, struct rusage *rusage); pid_t wait4(pid_t pid, int *stat_loc, int options, struct rusage *rusage);返回值是子进程的编号
变量的说明:
pid_t pid:要等待的进程的进程ID。int *stat_loc:用于保存进程退出状态的指针。如果不关心进程的退出状态,可以传递NULL。int options:等待选项,可用于指定等待行为的一些附加选项。常见的选项包括WNOHANG(非阻塞等待)和WUNTRACED(等待暂停子进程状态)。struct rusage *rusage:用于保存子进程资源使用情况的结构体指针。如果不关心子进程的资源使用情况,可以传递NULL。stzt_loc是子进程终止的信息,如果是正常终止,宏WIFEEXITED(stat_loc)返回真,WEXITSTAUTS(stat_loc)可获取终止状态,如果是异常状态,宏WTERMSIG可获取终止进程的信号
我们来用一段代码实验一下上述知识点:
#include <iostream> #include<unistd.h> #include <sys/types.h> #include <sys/wait.h> using namespace std; int main() { //父进程 if(fork()>0) { int sts; pid_t pid=wait(&sts); cout<<"已经终止子进程的进程编号为:"<<pid<<endl; if(WIFEXITED(sts)) { cout<<"子进程正常退出"<<"子进程的退出状态为"<<WEXITSTATUS(sts)<<endl; } else { cout<<"子进程异常退出"<<"子进程的退出状态为"<<WTERMSIG(sts)<<endl; } } //子进程 else { sleep(30); cout<<"byebye"<<endl; exit(1); } }
 我们如果尝试使用kill指令去强行结束子进程:
我们如果尝试使用kill指令去强行结束子进程:


-
如果父进程很忙,我们可以考虑捕获
SIGCHLD信号,在信号处理函数里面调用wait()/waitpid()代码示例:
#include <iostream> #include <unistd.h> #include<sys/types.h> #include<sys/wait.h> using namespace std; void func(int signal) { int sts; pid_t pid=wait(&sts); cout<<"子进程pid为"<<pid<<endl; if(WIFEXITED(sts)) { cout<<"子进程正常退出\n"<<"子进程的退出状态为"<<WEXITSTATUS(sts)<<endl; } else { cout<<"子进程异常退出\n"<<"子进程的退出状态为"<<WTERMSIG(sts)<<endl; } } int main() { signal(SIGCHLD,func); if(fork()>0) { while(true) { sleep(1); cout<<"父进程忙碌中"<<endl; } } else { sleep(10); int *p=0; *p=10; exit(1); } }
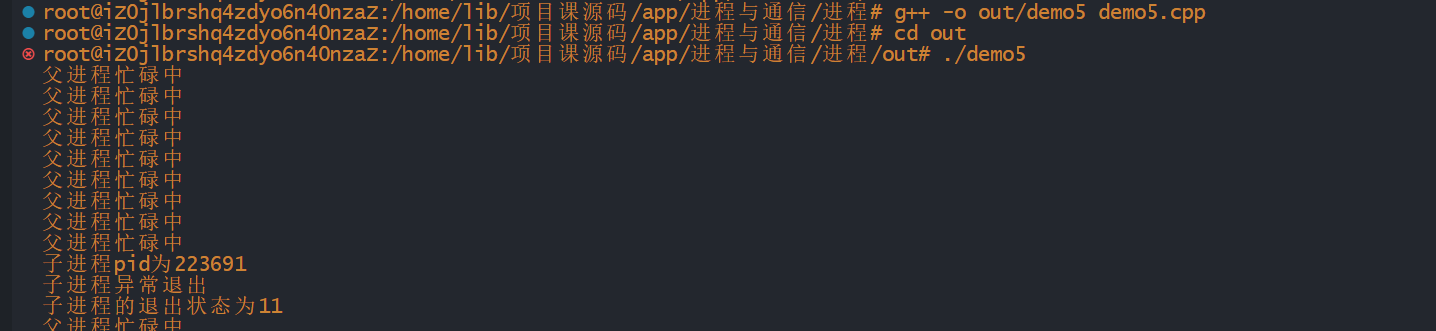
共享内存
前言
多线程之间共享进程的地址空间,所以如果多个线程需要访问同一块内存的话,使用全局变量即可
而在多进程中,我们上面也说到每个进程之间往往地址空间都是独立的,不共享的,如果多个进程需要访问同一块内存,这个时候是不能使用全局变量的,只能使用共享内存
共享内存允许多个进程(并不要求进程与进程之间有血缘关系)访问同一块内存空间,这是多个进程之间共享与传送数据最高效的方式.进程可以将共享内存链接到它们自己的内存空间中,如果某个进程修改了共享内存中的数据,其他的进程所读取到的数据也会改变。
共享内存没有提供锁机制,这意味着,在某一个进程对共享内存进行读/写的时候,不会阻止其他进程对其的读/写,如果要对共享内存的读/写加锁,可以使用信号量。
shmget函数
shmget()函数用于创建/获取共享内存
函数形式:
int shmget(key_t key,size_t size, int shmflg)
注释:
key:共享内存的键值,是一个整数,一般采取16进制,不同共享内存的key不能相同
size:共享内存的大小
shmflg:共享内存的访问权限,与文件权限一样
代码示例
//创建/获取共享内存
int shmid=shmget(0x5500,sizeof(gril),IPC_CREAT|0666);
if(shmid==-1)
{
cout<<"shmget(0x5500) failed"<<endl;
}
cout<<"shmid="<<shmid<<endl;
return 0;
输出为:

我们可以尝试查看系统当前的共享内存

我们也可以删除共享内存
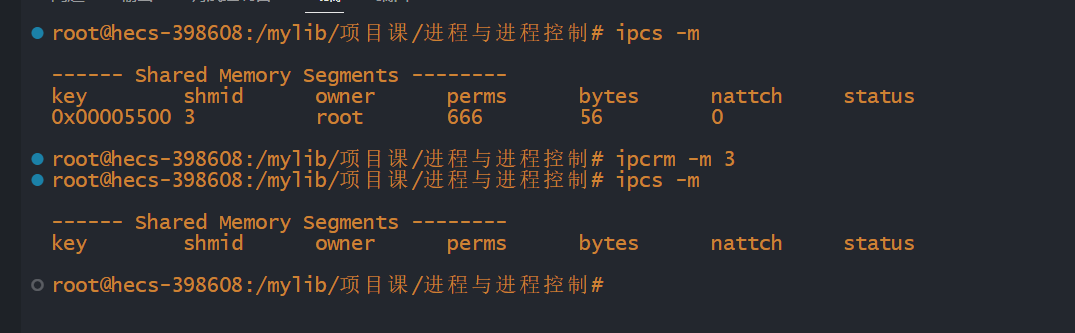
shmat函数
我们可以提供shmat()函数来将共享内存链接到当前进程的地址空间
函数形式:
void* shmat(int shmid,const void *shmaddr,int shmflg);
注释:
shmid:由shmget()返回的共享空间标识
shmaddr:指定共享内存连接到当前进程的具体位置,一般填0,表示让系统来选择共享内存的地址。
shmflg:标志位,一般填0
shmdt函数
如果我们想将共享内存从当前进程中分离,相当于shmat()函数的反操作
函数形式:
int shmdt(const void *shmaddr)
shmaddr:shmat()函数返回的地址。
shmctl函数
我们一般会使用shmctl()函数来操作共享内存,最常见的就是删除共享内存
int shmctl(int shmid,int command,struct shmid_ds *buf)
注释:
command:操作共享内存的命令
buf:操作共享内存的数据结构的地址
综合示例
#include <iostream>
#include<cstdio>
#include<cstring>
#include<unistd.h>
#include<sys/ipc.h>
#include<sys/shm.h>
using namespace std;
struct gril
{
int no; //编号;
char name[50];//姓名
};
int main(int argc,char* argv[])
{
//创建/获取共享内存
int shmid=shmget(0x5500,sizeof(gril),IPC_CREAT|0666);
if(shmid==-1)
{
cout<<"shmget(0x5500) failed"<<endl;
}
cout<<"shmid="<<shmid<<endl;
//连接共享内存到当前进程的地址空间
gril *gril_ptr=(gril*)shmat(shmid,0,0);
if(gril_ptr==(void*)-1)
{
cout<<"shmat() failed"<<endl;
}
//对共享内存进行读写
cout<<"原值 gril_ptr->no="<<gril_ptr->no<<endl;
cout<<"原值 gril_ptr->name="<<gril_ptr->name<<endl;
gril_ptr->no=atoi(argv[1]);
strcpy(gril_ptr->name,argv[2]);
cout<<"修改后的值 gril_ptr->no="<<gril_ptr->no<<endl;
cout<<"修改后的值 gril_ptr->name="<<gril_ptr->name<<endl;
//断开连接
shmdt(gril_ptr);
//删除共享内存
if(shmctl(shmid,IPC_RMID,0)==-1)
{
cout<<"shmctl(IPC_RMID) failed"<<endl;
}
return 0;
}
进程通信方式——管道
什么是管道
管道是进程间通信的一种方式,它的本质其实是内核中的一块内存(或者说是内核缓冲区),这块区域的数据存储在一个环形队列,不过由于管道使用的是内核里面 的内存,所以我们无法对管道里面的数据进行直接操作,只能在管道的两端读/写数据。
管道的特点
-
管道数据是基于队列来维护的
-
管道对应的内核缓冲区大小的固定,默认4K
-
管道分为两部分:读端和写端(队列的两端),数据从写端进入管道,从端流出管道
-
管道的数据只能读一次,可以理解数据是在管道里面流动,由一端流向另一端.
-
对管道的操作(读,写)默认是阻塞的
- 读管道:管道中没有数据,读操作被阻塞,当管道中有数据之后阻塞才能解除。
- 写管道:管道被写满了,写数据的操作被阻塞,当管道变为不满的状态,写阻塞解除。
- Linux的文件IO函数:
ssize_t read(int fd,void *buf,size_t count); ssize_t write(int fd,const void *buf,size_t count);
匿名管道
匿名管道的创建
匿名管道是管道的一种,匿名主要是指管道没有名字,但是本质是不变,它有管道的所有特性,匿名管道只能实现有血缘关系的进程间通信(父子进程,兄弟进程,爷孙进程,叔侄进程)
#include <unistd.h>
int pipe(int pipefd[2]);
- 参数:传出参数,需要传递一个整形数组的地址,数组大小为 2,也就是说最终会传出两个元素
- pipefd[0]: 对应管道读端的文件描述符,通过它可以将数据从管道中读出
- pipefd[1]: 对应管道写端的文件描述符,通过它可以将数据写入到管道中
- 返回值:成功返回 0,失败返回 -1
进程间的通信
在讲解进程间通过管道的提醒具体内容之前,我们先来看一个简单的样例:
#include <iostream>
#include <cstring>
#include <unistd.h>
#include <fcntl.h>
#include <errno.h>
#include <sys/wait.h>
#include <sys/types.h>
using namespace std;
int main()
{
int fd[2] ;//定义两个文件描述符
int ret=pipe(fd); //创建管道
if(ret==-1)
{
perror("pipe error");
}
int pid=fork(); //创建子进程
if(pid==0)
{
close(fd[0]);
/*这里子进程关闭读端,保留写端,这里我们希望将原来的在终端输出的内容改为输入到管道给父进程读取*/
dup2(fd[1],STDOUT_FILENO);//将输出位置重定向到管道上
execlp("ps","ps","aux",NULL);
perror("execlp error");
}
else if(pid>0) //执行父进程操作
{
close(fd[1]); //关闭写端
char buff[1024];
//读管道
//管道无数据——> read函数阻塞
//管道有数据——> read停止阻塞(如果正处于阻塞状态),读取数据(若管道已满,写操作阻塞);
while(true)
{
sleep(5);
memset(buff,0,sizeof(buff));
int len=read(fd[0],buff,sizeof(buff));
if(len==0) cout<<"pipe is empty"<<endl;
cout<<"buff:"<<buff<<" "<<"len:"<<len<<endl;
}
wait(NULL); //等待子进程结束回收资源
}
return 0;
}
备注
- 子进程中执行shell命令相对于启动一个磁盘程序,因此需求使用execl()/execlp()函数
- execlp("ps","ps","aux",NULL)
- 子进程中执行完shell命令直接就可以终端输出结果,这些消息传递父进程?
- 进程数据传递需要管道,子进程需要将数据写入管道,父进程需要从管道中读取数据
- 这里子进程想将终端输出结果写入管道,因此需要将标准输出重定向到管道
- 这里父进程要等待子进程执行完shell命令释放子进程资源进而避免僵尸进程,因此需要使用wait()函数
有名管道
有名管道和匿名管道类似,但是有名管道可以用于无亲缘关系的进程间通信,之所以叫有名管道,是因为它在磁盘上有一个文件,类型为p,它的大小为0,因为它的内容还是存储在 内存缓存区,但是我们打开它可以获取文件蛮舒服,进而基于它们我们可以实现无血缘关系进程之间的通讯,同时由于有名管道式一个文件实体,所以我们创建文件时渝新欧下面两种:
- 基于shell命令创建
mkfifo filename
- 基于C语言创建
#include<sys/types.h>
#include<sys/stat.h>
int mkfifo(const char *pathname, mode_t mode);
- 参数
- pathname:文件名
- mode:权限
- 返回值
- 成功:0
- 失败:-1
基于有名管道实现进程间通信
- 写进程
// 有名管道的写端
#include <string>
#include <iostream>
#include <fcntl.h>
#include <unistd.h>
#include <cstdio>
#include <sys/stat.h>
#include <sys/types.h>
#include <sys/wait.h>
#include <cerrno>
#include <cstdlib>
#include <string.h>
using namespace std;
int main()
{
int wfd=open("./testfifo",O_WRONLY);
if(wfd==-1)
{
perror("open");
return -1;
}
cout<<"open success"<<endl;
int i=0;
while(i<100)
{
char str[1024];
memset(str,0,sizeof(str));
sprintf(str,"hello world %d\n",i);
int wn=write(wfd,"hello world",strlen("hello world"));
if(wn<0)
{
cerr<<"错误码:"<<errno<<",错误原因:"<<strerror(errno)<<endl;
break;
}
if(wn>0)
{
cout<<"write "<<wn<<" bytes"<<endl;
}
i++;
sleep(1);
}
close(wfd);
return 0;
}
- 读进程
#include <iostream>
#include <fcntl.h>
#include <unistd.h>
#include <sys/stat.h>
#include <cstring>
using namespace std;
int main()
{
int rfd = open("./testfifo", O_RDONLY);
if (rfd == -1)
{
perror("open");
return -1;
}
char buf[1024];
while (true)
{
memset(buf, 0, sizeof(buf));
int len = read(rfd, buf, sizeof(buf) - 1); // 减去1以防止覆盖结束符
if (len >0) cout<<"receive: "<<buf<<endl;
}
close(rfd); // 关闭文件描述符
return 0;
}
管道描述符的修改
// 管道操作眼需要创建对应两个文件描述符, 分别是管道的读端和写端,但是创建完管道后也可以将它们对应的属性进行修改(比如将阻塞改为非阻塞),步骤如下:
// 1. 获取读端的文件描述符的flag属性
int flag = fcntl(fd[0], F_GETFL);
// 2. 添加非阻塞属性到 flag中
flag |= O_NONBLOCK;
// 3. 将新的flag属性设置给读端的文件描述符
fcntl(fd[0], F_SETFL, flag);
// 4. 非阻塞读管道
char buf[4096];
read(fd[0], buf, sizeof(buf));
备注:虽然可以修改但是一般不建议这么做,这里涉及的仅供参考。
进程通信——内存映射
什么是内存映射
内存映射是一种将文件内容映射到进程地址空间的技术,使得进程可以直接访问文件内容,而不需要通过系统调用进行读写操作。内存映射可以提高文件访问的效率,并且可以实现进程间的通信。
内存映射的原理
我们在进程中创建一个内存映射区,但由于这个内存映射区是创建在进程的地址空间中,所以外界的进程空间无法直接访问其他进程的内存映射区。但是,我们可以通过系统调用mmap将文件内容映射到内存映射区,这样进程就可以直接访问文件内容了,像下面这样:
 如上图那样,磁盘文件数据不仅可以完全加载到进程的内存映射区,还可以部分加载到进程的内存映射区,当进程A中的内存映射区数据被修改了,数据会被自动同步到磁盘文件,同时和磁盘文件建立映射关系的其他进程内存映射区中的数据也会和磁盘文件进行数据的实时同步,基于这样的同步机制我们可以实现进程间的通信。
如上图那样,磁盘文件数据不仅可以完全加载到进程的内存映射区,还可以部分加载到进程的内存映射区,当进程A中的内存映射区数据被修改了,数据会被自动同步到磁盘文件,同时和磁盘文件建立映射关系的其他进程内存映射区中的数据也会和磁盘文件进行数据的实时同步,基于这样的同步机制我们可以实现进程间的通信。
内存映射的创建
内存映射的创建需要使用mmap函数,该函数的原型如下:
void *mmap(void *addr, size_t length, int prot, int flags, int fd, off_t offset);
参数说明:
addr: 指定映射区的起始地址,如果为NULL,则由系统自动选择一个地址。length: 指定映射区的长度。prot: 指定映射区的保护方式,可以是以下值的组合:PROT_READ: 可读。如果映射区被修改,则修改的内容会被同步到文件。PROT_WRITE: 可写。如果映射区被修改,则修改的内容会被同步到文件。PROT_EXEC: 可执行。PROT_NONE: 无权限。
flags: 指定映射区的标志,可以是以下值的组合:MAP_SHARED: 共享映射区。多个进程可以共享同一个映射区。MAP_PRIVATE: 私有映射区。每个进程都有自己的映射区,修改不会影响其他进程。MAP_ANONYMOUS: 匿名映射区。不与文件关联,可以用于进程间的通信。
fd: 指定要映射的文件的文件描述符。offset: 指定映射区的起始偏移量。
返回值:
- 成功返回映射区的起始地址。
- 失败返回
MAP_FAILED。
由于参数较多,一般我们可以像下面这样创建:
- 第一个参数 addr 指定为 NULL 即可
- 第二个参数 length 必须要 > 0
- 第三个参数 prot,进程间通信需要对内存映射区有读写权限,因此需要指定为:PROT_READ | PROT_WRITE
- 第四个参数 flags,如果要进行进程间通信, 需要指定 MAP_SHARED
- 第五个参数 fd,打开的文件必须大于0,进程间通信需要文件操作权限和映射区操作权限相同
- 内存映射区创建成功之后, 关闭这个文件描述符不会影响进程间通信
- 第六个参数 offset,不偏移指定为0,如果偏移必须是4k的整数倍
内存映射的释放
既然我们创建了内存映射区,那么在不需要的时候就需要释放它,释放内存映射区需要使用munmap函数,该函数的原型如下:
int munmap(void *addr, size_t length);
参数说明:
addr: 指定要释放的映射区的起始地址。length: 指定要释放的映射区的长度。
返回值:
- 成功返回0。
- 失败返回-1。
基于内存映射区实现进程间通信
内存映射区与管道通信的区别
-
管道通信是使用文件描述符进行通信,而内存映射区通信是直接使用内存地址进行通信。这导致了管道通信是阻塞的,而内存映射区通信是非阻塞的。
-
管道通信的数据需要经过内核缓冲区,而内存映射区通信的数据直接在用户空间和内核空间之间传递,不需要经过内核缓冲区。这导致了内存映射区通信的速度更快。
基于内存映射实现的进程通信
有血缘关系的进程通信
#include <iostream>
#include <sys/types.h>
#include <sys/mman.h>
#include <sys/stat.h>
#include <cstring>
#include <unistd.h>
#include <wait.h>
#include <fcntl.h>
using namespace std;
int main()
{
int fd = open("test.txt", O_RDWR | O_CREAT, 0666);
if (fd == -1)
{
perror("open");
return -1;
}
cout<<111<<endl;
void* ptr = mmap(NULL, 4000, PROT_READ | PROT_WRITE, MAP_SHARED, fd, 0);
if (ptr == MAP_FAILED)
{
perror("mmap");
return -1;
}
int pid = fork();
if (pid > 0) // 父进程
{
const char* str = "test";
cout<<222<<endl;
// 确保字符串正确终止
memcpy(ptr, str, strlen(str) + 1);
// 等待一段时间,确保子进程有机会读取数据
sleep(5); // 使用 sleep(1) 替代 usleep(1),确保子进程有足够时间读取
}
else if (pid == 0) // 子进程
{
// 读取数据
cout << "从内存映射区读取出来的数据: " << static_cast<char*>(ptr) << endl;
}
// 确保父进程等待子进程结束
wait(NULL);
// 解除映射并关闭文件
munmap(ptr, 4000);
close(fd);
return 0;
}
备注: mmap不能去扩展一个内容为空的新文件,因为大小为0,所有本没有与之对应的合法的物理页,不能扩展。我们需要在新创建的空文件中先写入一些数据,否则会报错bus error(总线错误)
无血缘关系的进程通信
//
// 写端
#include <iostream>
#include <sys/types.h>
#include <sys/mman.h>
#include <sys/stat.h>
#include <cstring>
#include <unistd.h>
#include <wait.h>
#include <fcntl.h>
using namespace std;
int main()
{
int fd=open("test.txt",O_RDWR);
if(fd==-1)
{
perror("open");
return -1;
}
void* ptr=mmap(NULL,4096,PROT_READ|PROT_WRITE,MAP_SHARED,fd,0);
if(ptr==MAP_FAILED)
{
perror("mmap");
return -1;
}
const char* str="test";
memcpy(ptr,str,strlen(str)+1);
munmap(ptr,4096);
return 0;
}
//读端
#include <iostream>
#include <cstring>
#include <fcntl.h>
#include <unistd.h>
#include <sys/mman.h>
using namespace std;
int main()
{
int ret=open("test.txt",O_RDWR);
if(ret==-1)
{
perror("open");
return -1;
}
void* ptr=mmap(NULL,4096,PROT_READ|PROT_WRITE,MAP_SHARED,ret,0);
if(ptr==MAP_FAILED)
{
perror("mmap");
return -1;
}
cout<<"ptr:"<<(char*)ptr<<endl;
munmap(ptr,4096);
return 0;
}
基于内存映射实现文件拷贝
我们除了使用文件拷贝函数,也可以使用内存映射区实现文件拷贝,下面就是我们如何基于内存映射实现文件拷贝
#include <iostream>
#include <cstring>
#include <cstdio>
#include <cstdlib>
#include <sys/mman.h>
#include <fcntl.h>
#include <unistd.h>
using namespace std;
int main()
{
//打开待复制的文件
int fd1=open("test.txt", O_RDONLY);
if(fd1==-1)
{
perror("open");
return 0;
}
//获取待复制文件的大小
int size=lseek(fd1, 0, SEEK_END);
//创建源文件的内存映射区
void* ptr1=mmap(NULL, size, PROT_READ, MAP_SHARED, fd1, 0);
if(ptr1==MAP_FAILED)
{
perror("mmap");
return 0;
}
//打开目标文件
int fd2=open("test2.txt", O_RDWR|O_CREAT|O_TRUNC, 0666);
if(fd2==-1)
{
perror("open");
return 0;
}
//创建目标文件的内存映射区
void* ptr2=mmap(NULL, size, PROT_READ|PROT_WRITE, MAP_SHARED, fd2, 0);
if(ptr2==MAP_FAILED)
{
perror("mmap");
return 0;
}
//拓展文件大小,避免出现总线错误
ftruncate(fd2, size);
//拷贝文件
memcpy(ptr2, ptr1, size);
//关闭文件
close(fd1);
close(fd2);
//解除内存映射区
munmap(ptr1, 4096);
munmap(ptr2, size);
return 0;
}
信号量
循环队列
前言
在我们使用共享内存的时候,我们一般要注意以下几点:
- 共享内存无法自动拓展,我们只能使用c++内置的数据类型
- 共享内存不能采用STL日期,也不能使用移动语义
而在我们日常对共享内存进行操作的时候,主要还是以队列为主
代码示例
//public.h
#ifndef _PUBLIC_HH
#define _PUBLIC_HH
#include<iostream>
#include<cstring>
#include<cstdio>
#include<sys/shm.h>
#include<sys/ipc.h>
#include<unistd.h>
template<typename TT,int MaxLength>
class squeue
{
private:
bool M_inited;//判断队列是否已经被初始化
TT M_data[MaxLength];//存储数据的数组
int M_head;//队头指针
int M_tail;//队尾指针
int length;//队列中实际元素的数量
squeue(const squeue &) =delete;//禁止拷贝构造函数
squeue& operator=(const squeue &) =delete;//禁止直接赋值
public:
squeue() {init();} //构造函数
void init()
{
if(M_inited!=true)
{
M_inited=true;
M_head=0;
M_tail=MaxLength-1;
length=0;
sizeof(M_data,0,sizeof(M_data));
}
}
bool push(TT& ee)
{
if(length==MaxLength)
{
std::cout<<"the queue is full"<<std::endl;
return false;
}
M_tail=(M_tail+1)%MaxLength;
M_data[M_tail]=ee;
length++;
return true;
}
int getSize()
{
return length;
}
bool isFull()
{
return length==MaxLength;
}
TT& front()
{
return M_data[M_head];
}
bool pop()
{
if(length==0)
{
std::cout<<"the queue is empty"<<std::endl;
return false;
}
M_head=(M_head+1)%MaxLength;
length--;
return true;
}
~squeue() {} //析构函数
};
#endif // __PUBLIC_HH
//共享内存下的循环队列.cpp
#include "public.h"
using namespace std;
struct gril
{
int no;
char name[20];
};
int main()
{
squeue<gril,5> q;
//初始化共享内存
int shmid=shmget(0x5550,sizeof(q),0666|IPC_CREAT);
if(shmid==-1)
{
cout<<"shmget(0x5550) failed"<<endl;
return -1;
}
cout<<"shmid="<<shmid<<endl;
//将共享内存连接到当前进程的地址空间
squeue<gril,5>* q_ptr=(squeue<gril,5>*)shmat(shmid,0,0);
if(q_ptr==(void*)-1)
{
cout<<"shmat failed"<<endl;
return -1;
}
//对共享内存进行读写
q.init();
gril a[5];
for(int i=0;i<5;i++)
{
a[i].no=i;
strcpy(a[i].name,"girl");
q.push(a[i]);
}
for(int i=0;i<3;i++)
{
q.pop();
}
cout<<"队列的长度为"<<q.getSize()<<endl;
//断开连接
shmdt(q_ptr);
return 0;
}
信号量
信号量的基本概念
- 信号量本质上是一个是一个非负数的计数器,用于给共享资源创建一个标志,来表示该共享资源的被占用情况
信号量的两种操作
- P操作:将信号量的值减一,如果信号量的值为0,则会阻塞等待,直到信号量的值再次大于0
- V操作:将信号量得值加一,任何时候都不会阻塞
信号量的应用场景
- 如果约定的信号量的取值只是0和1(0-资源不可用;1-资源可用),我们可以实现互斥锁
- 如果约定信号量的取值表示可用资源的数量,可以实现生产/消费者模型
常用函数
-
semop函数
semop函数是 Linux 系统调用,用于对指定的信号量进行操作。它通常由sem_t类型的结构体作为参数,用于对信号量的操作,如信号量的初始化、等待和通知等。semop函数的定义在unistd.h头文件中,通常在 C 语言中使用。在 Linux 系统中,信号量用于同步和通信,可以用来实现线程之间的同步。信号量可以有多个,每个信号量代表一个资源,线程可以通过等待和通知来访问这些资源。semop函数就是线程用于对信号量进行操作的重要接口。int semop(const struct sem_t *set, unsigned int nsems, int cmd);参数
set是一个sem_t类型的结构体数组,用于存放信号量操作的参数。nsems是一个无符号整数,表示set数组中信号量的数量。cmd是一个整数,表示要执行的信号量操作。这个值可以是以下几种:SEM_WAIT:等待信号量可用。SEM_POST:释放信号量到一个就绪的线程。SEM_INIT:初始化信号量。SEM_DESTROY:销毁信号量。
semop函数返回一个整数,表示信号量操作的成功与否。如果操作成功,返回0;否则返回-1。
示例代码
//public.h
#include <iostream>
#include <cstring>
#include <sys/types.h>
#include <sys/ipc.h>
#include <sys/sem.h>
using namespace std;
//信号量
class csemp
{
private:
union semun //用于操控共享内存的联合体
{
int value;
struct semid_ds *buf;
unsigned short *arry;
};
int m_semid; //信号量id
/*如果将m_semflg设为SEM_UNOD,操作系统将跟踪进程对信号量的修改,在全部修改过信号量的进程终止后将信号量设置为初始值
m_semflag=1时用于互斥锁,m_semflag=0时用于生产消费者模型*/
short m_semflg; //信号量值
csemp(const csemp&) =delete; //禁用拷贝构造函数
csemp& operator=(const csemp&) =delete; //禁用赋值运算符
public:
csemp():m_semid(-1){}
/*如果信号量已存在,就获取信号量
如果信号量不存在,就创建信号量并将其初始化为value
互斥锁时,value=1,semflag=SEM_UNOD
生产消费者模型时,value=0,semflag=0*/
bool init(key_t key,unsigned short value=1,short semflg=SEM_UNDO);
bool wait(short value=-1); //P操作
bool post(short value=1); //V操作
int getvalue();
bool destroy();
~csemp();
};
//循环队列
template<typename T,int MaxLength>
class squeue
{
private:
int m_inited=-1;
int m_head;
int m_tail;
int m_length;
T m_data[MaxLength];
squeue(const squeue&)=delete;
squeue& operator=(const squeue&)=delete;
public:
squeue(){init();}
bool init()
{
if(m_inited!=-1) return false;
m_inited=1;
m_head=0;
m_tail=0;
m_length=0;
memset(m_data,0,sizeof(m_data));
return true;
}
bool push(const T& data)
{
if(full()) return false;
m_data[m_tail]=data;
m_tail=(m_tail+1)%MaxLength;
m_length++;
return true;
}
bool pop()
{
if(empty()) return false;
m_data[m_head]=0;
m_head=(m_head+1)%MaxLength;
m_length--;
return true;
}
bool empty()
{
return m_length==0;
}
bool full()
{
return m_length==MaxLength;
}
int size()
{
return m_length;
}
T& front()
{
return m_data[m_head];
}
void Print()
{
for(int i=m_head;i<m_tail;i++)
{
cout<<m_data[i]<<" ";
}
}
~squeue(){}
};
//public.cpp
#include "public.h"
bool csemp::init(key_t key,unsigned short value,short semflg)
{
if(m_semid!=-1) //信号量已经初始化了
{
return false;
}
m_semflg=semflg;
if((m_semid=semget(key,1,0666))==-1) //尝试获取信号量
{
if(errno==ENOENT) //未找到信号量
{
if((m_semid=semget(key,1,IPC_CREAT|0666|IPC_EXCL))==-1) //创建信号量
{
if(errno==EEXIST)//信号量已存在
{
if((m_semid=semget(key,1,0666))==-1)
{
perror("init semget 1");
return false;
}
return true;
}
else
{
perror("init semget 2");
return false;
}
}
union semun b;
b.value=value;
if(semctl(m_semid,0,SETVAL,b)==-1) //设置信号量初值
{
perror("init semctl");
return false;
}
}
else
{
perror("init semget 3");
return false;
}
}
return true;
}
bool csemp::wait(short value)
{
if(m_semid==-1) return false;
struct sembuf s;
s.sem_num=0;
s.sem_op=value;
s.sem_flg=m_semflg;
if(semop(m_semid,&s,1)==-1)
{
perror("wait semop");
return false;
}
return true;
}
bool csemp::post(short value)
{
if(m_semid==-1) return false;
struct sembuf s;
s.sem_num=0;
s.sem_op=value;
s.sem_flg=m_semflg;
if(semop(m_semid,&s,1)==-1)
{
perror("post semop");
return false;
}
return true;
}
int csemp::getvalue()
{
return semctl(m_semid,0,GETVAL);
}
bool csemp::destroy()
{
if(m_semid==-1) return false;
if(semctl(m_semid,0,IPC_RMID)==-1)
{
perror("destroy semctl");
return false;
}
return true;
}
csemp::~csemp()
{
}
//Shared_Memory3.cpp
/*本程序演示用信号量给共享内存加锁。*/
#include "public.h"
#include <iostream>
#include <sys/ipc.h>
#include <sys/shm.h>
#include <sys/wait.h>
#include <unistd.h>
#include <semaphore.h>
using namespace std;
struct gril
{
int no;
char name[20];
};
int main(int argc,char* argv[])
{
int shmid=shmget(0x5550,sizeof(gril),IPC_CREAT|0666);
if(shmid==-1)
{
perror("shmget");
return -1;
}
cout<<"shmid="<<shmid<<endl;
//将共享内存绑定到当前进程的地址空间
gril* p=(gril*)shmat(shmid,NULL,0);
if(p==(void*)-1)
{
perror("shmat");
return -1;
}
cout<<"shmat ok"<<endl;
//加锁
csemp mutex;
mutex.init(0x5550);
cout<<"正在加锁中"<<endl;
mutex.wait();
cout<<"加锁成功"<<endl;
//操作共享内存
p->no=atoi(argv[1]);
strcpy(p->name,argv[2]);
cout<<p->no<<" "<<p->name<<endl;
sleep(20);
//解锁
mutex.post();
cout<<"解锁成功"<<endl;
//解除共享内存的绑定
shmdt(p);
//删除共享内存
if(shmctl(shmid,IPC_RMID,NULL)==-1)
{
perror("shmctl");
return -1;
}
return 0;
}
使用的编译命令:
all: demo1
demo1:Shared_Memory3.cpp public.h public.cpp
g++ -std=c++11 -o demo1 Shared_Memory3.cpp public.cpp
clean:
rm -f demo1
多进程下的服务端
// server.h
#include <iostream>
class Server
{
private:
int m_listenfd; // 监听套接字
int m_clientfd; // 客户端套接字
unsigned m_server_port; //服务端端口号
std::string m_client_ip; // 客户端IP地址
public:
Server();
bool InitServer(const unsigned short& port);
bool Accept();
bool Send(const std::string& buff);
bool Recv(std::string& buff,int max_len);
bool closeClientfd();
bool closeListenfd();
const std::string& getClientip();
~Server();
};
void FatherExit(int sig); // 父进程退出信号处理函数
void ChildExit(int sig); // 子进程退出信号处理函数
//server.cpp
#include "server.h"
#include <cstring>
#include <cstdlib>
#include <unistd.h>
#include <signal.h>
#include <netinet/in.h>
#include <arpa/inet.h>
#include <sys/wait.h>
#include <sys/types.h>
#include <sys/socket.h>
using namespace std;
Server::Server(): m_clientfd(-1),m_listenfd(-1){}
bool Server::InitServer(const unsigned short& port)
{
if((m_listenfd=socket(AF_INET,SOCK_STREAM,0))==-1)
{
return false;
}
struct sockaddr_in server_addr;
memset(&server_addr,0,sizeof(server_addr));
server_addr.sin_family=AF_INET;
server_addr.sin_port=htons(port);
server_addr.sin_addr.s_addr=htonl(INADDR_ANY);
if(bind(m_listenfd,(struct sockaddr*)&server_addr,sizeof(server_addr))==-1)
{
close(m_listenfd);
return false;
}
if(listen(m_listenfd,5)==-1)
{
close(m_listenfd);
return false;
}
return true;
}
bool Server::Accept()
{
struct sockaddr_in client_addr;
socklen_t client_addr_len=sizeof(client_addr);
if((m_clientfd=accept(m_listenfd,(struct sockaddr*)&client_addr,&client_addr_len))==-1)
{
return false;
}
m_client_ip=inet_ntoa(client_addr.sin_addr);
return true;
}
bool Server::Send(const string& buff)
{
if(m_clientfd==-1)
{
return false;
}
if(send(m_clientfd,buff.c_str(),buff.size(),0)==-1)
{
return false;
}
return true;
}
bool Server::Recv(string& buff,int maxlen)
{
buff.clear();
buff.resize(maxlen);
int readn=recv(m_clientfd,&buff[0],buff.size(),0);
if(readn<=0)
{
buff.clear();
return false;
}
buff.resize(readn);
return true;
}
bool Server::closeClientfd()
{
if(m_clientfd==-1) return false;
close(m_clientfd);
return true;
}
bool Server::closeListenfd()
{
if(m_listenfd==-1) return false;
close(m_listenfd);
return true;
}
const string& Server::getClientip()
{
return m_client_ip;
}
Server::~Server()
{
closeClientfd();
closeListenfd();
}
Server server;
int main(int argc,char* argv[])
{
if(argc!=2)
{
cout<<"Example: ./demo port"<<endl;
return -1;
}
//先忽略掉所有的信号,后面再对它们进行专门的处理
for(int i=1;i<=64;i++)
{
signal(i,SIG_IGN);
}
signal(2,FatherExit); //SIGINT Ctrl+c
signal(15,FatherExit); //SIGTERM kill
if(!server.InitServer(atoi(argv[1])))
{
perror("InitServer");
return -1;
}
while(true)
{
if(!server.Accept())
{
perror("Accept");
return -1;
}
cout<<"Accept from "<<server.getClientip()<<endl;
int pid=fork();
if(pid==-1)
{
perror("fork"); //系统资源不足
return -1;
}
else if(pid>0)
{
server.closeClientfd(); //父进程只需要处理客户端的连接请求,无需与客户端进行通信,因此关闭客户端套接字
continue; //让父进程返回继续接收客户端的连接申请
}
server.closeListenfd(); //子进程不需要监听客户端的连接请求,因此关闭监听套接字
signal(15,ChildExit);
signal(2,SIG_IGN); //重新设置子进程退出信号
cout<<"客户端已连接"<<server.getClientip()<<endl;
string buff;
while (true)
{
// 接收对端的报文,如果对端没有发送报文,recv()函数将阻塞等待。
if (server.Recv(buff,1024)==false)
{
perror("recv()"); break;
}
cout << "接收:" << buff<< endl;
buff="ok";
if (server.Send(buff)==false) // 向对端发送报文。
{
perror("send"); break;
}
cout << "发送:" << buff << endl;
}
}
}
void FatherExit(int sig)
{
//暂时忽略其他信号,避免对操作造成干扰
signal(SIGINT,SIG_IGN);
signal(SIGTERM,SIG_IGN);
cout<<"父进程正在退出"<<endl;
server.closeListenfd(); //关闭监听套接字
kill(0,SIGTERM); //向所有子进程发送SIGTERM信号
exit(0);
}
void ChildExit(int sig)
{
//暂时忽略其他信号,避免对操作造成干扰
signal(SIGINT,SIG_IGN);
signal(SIGTERM,SIG_IGN);
cout<<"子进程"<<getpid()<<"正在退出,sig="<<sig<<endl;
server.closeClientfd(); //关闭客户端套接字
server.closeClientfd(); //关闭客户端套接字
exit(0);
}
all: demo1
demo1:
g++ -o demo1 server.cpp
clean:
rm -f demo1
多进程下的生产消费者模型
什么是生产消费者模型
生产者-消费者模式是一种经典的并发编程模式,用于解决生产者与消费者之间进行数据交换与同步问题,在多线程/进程环境下,生产者负责生成数据并将其放入共享的数据缓冲区,而消费者负责从数据缓冲区中取出数据并进行处理,生产者和消费者通过共享的数据缓冲区进行通信,而我们这样做的原因是在实际生产中生产者与消费者的速度往往是不同的,而我们需要保证进程/线程之间的同步与协作
相关概念
- 生产者:负责生成数据并将其放入共享的数据缓冲区中
- 消费者:负责从共享的数据缓冲区中取出数据并进行处理
- 数据缓冲区:用于生产者和消费者之间进行数据交换的共享空间,通常是一个 队列或者缓冲区。
示例demo
//生产者
#include "../public.h"
struct stgril
{
int no;
char name[20];
};
using ee=stgril;
int main()
{
stgril s1,s2,s3;
s1.no=1;
s2.no=2;
s3.no=3;
strcpy(s1.name,"s1");
strcpy(s2.name,"s2");
strcpy(s3.name,"s3");
//创建共享内存
int shmid=shmget(0x5550,sizeof(squeue<stgril,5>),0666|IPC_CREAT);
if(shmid<0)
{
perror("shmget failed");
return -1;
}
//将共享内存连接到当前进程的地址空间
squeue<stgril,5>* q=(squeue<stgril,5>*)shmat(shmid,0,0);
if(q==(void*)-1)
{
perror("shmat failed");
return -1;
}
q->init();
csemp mutex;
csemp cond;
mutex.init(0x5001);
cond.init(0x5002,0,0);
mutex.wait(); //加锁
q->push(s1);
q->push(s2);
q->push(s3);
mutex.post(); //解锁
cond.post(3); //设置信号量,表示生产者生成3个数据
shmdt(q);
return 0;
}
//消费者
#include "../public.h"
#include <unistd.h>
struct stgril
{
int no;
char name[20];
};
using st = stgril;
int main()
{
// 获取共享内存
int shmid = shmget(0x5550, sizeof(squeue<stgril, 5>), 0666 | IPC_CREAT);
if (shmid < 0)
{
perror("shmget");
return -1;
}
// 将共享内存连接到当前进程的地址空间
squeue<stgril, 5> *p = (squeue<stgril, 5> *)shmat(shmid, 0, 0);
if (p == (void *)-1)
{
perror("shmat");
return -1;
}
p->init();
csemp mutex;
csemp cond;
mutex.init(0x5001);
cond.init(0x5002, 0, 0);
while (true)
{
mutex.wait();
while (p->empty())
{
mutex.post();
cond.wait();
mutex.wait();
}
st a = p->front();
p->pop();
mutex.post();
cout << "no=" << a.no << " name=" << a.name << endl;
sleep(5);
}
// 断开共享内存
shmdt(p);
}
守护进程
前言
在前面我们已经实现过调度模块和进程的心跳模块了,而今天我们要讲的是作为服务端后台服务程序运行三个通用模块的最后一项:进程的守护模块,在开始讲解进程的守护模块之前我们首先来看究竟什么是进程的守护模块:
守护模块(有时也称为守护进程或守护服务)可以是软件架构的一部分,用于确保关键进程的稳定运行和系统的整体健壮性。
守护模块的主要职责可能包括但不限于:
- 进程监控:定期检查进程的状态,确认它们是否正在运行且运行正常。
- 异常恢复:如果检测到进程已停止或进入不稳定状态,守护模块可以采取行动,比如重启进程,以恢复服务的正常运行。
- 资源管理:管理进程的资源使用情况,例如内存和 CPU 使用率,防止资源耗尽。
- 日志记录和报警:记录进程的状态变化和异常情况,必要时发送警告给系统管理员。
- 配置更新:当系统配置发生变化时,守护模块可以负责更新相关进程的配置,并重启进程以应用新的设置。
- 安全和访问控制:确保进程在安全的环境中运行,限制对外部的访问,防止未授权的操作。
接下来我们来看一下,如何来实现一个简单的进程守护模块。
进程守护模块的初步实现
首先我们来看一下如何初步实现一个简单的进程守护模块,实现的流程图如下:

然后我们就可以着手来实现这个守护模块:
1.打开日志文件 这里我们选择将日志文件名作为命令行参数输入,所以这里的实现可以向下面这样:
clogfile logfile;
if (logfile.open(argv[1])==false)
{
cout<<"log.open"<<argv[1]<<"failed."<<endl;
}
备注:这里的的clogfile类是博主自己封装的,大家可以根据自己的代码进行修改
2.创建/获取共享内存
int shmid=shmget((key_t)SHMKEYP, MAXNUM*sizeof(struct st_procinfo), 0666|IPC_CREAT);
if(shmid==-1)
{
logfile.write("shmget failed.");
}
3.将共享内存连接到当下进程的地址空间
struct st_procinfo *st_info=(struct st_procinfo *)shmat(shmid,0,0);
if(st_info==(void *)-1)
{
logfile.write("shmat failed.");
}
4.遍历共享内存,将超时的进程进行处理
for(int i=0;i<MAXNUM;i++)
{
if(st_info[i].pid>0)
{
logfile.write("checkproc pid=%d,name=%s,timeout=%d,atime=%d",st_info[i].pid,st_info[i].name,st_info[i].timeout,st_info[i].atime); //主要用于测试
time_t now_time=time(NULL);
if(st_info[i].timeout<=now_time-st_info[i].atime)
{
logfile.write("%d号进程超时,终止。",st_info[i].pid);
kill(st_info[i].pid,9);
}
}
}
5.将共享内存分离出进程
shmdt(st_info);
最后就有我们初步的进程守护模块的代码了:
#include "../../public/_public.h"
using namespace idc;
int main(int argc,char* argv[])
{
if(argc!=2)
{
printf("\n");
printf("Using:./checkproc logfilename\n");
printf("Example:/root/mylib/project/tools/bin/procctl 10 /root/mylib/project/tools/bin/checkproc /tmp/log/checkproc.log\n\n");
printf("本程序用于检查后台服务程序是否超时,如果已超时,就终止它。\n");
printf("注意:\n");
printf(" 1)本程序由procctl启动,运行周期建议为10秒。\n");
printf(" 2)为了避免被普通用户误杀,本程序应该用root用户启动。\n");
printf(" 3)如果要停止本程序,只能用killall -9 终止。\n\n\n");
}
// 打开日志文件
clogfile logfile;
if (logfile.open(argv[1])==false)
{
cout<<"log.open"<<argv[1]<<"failed."<<endl;
}
//创建/获取共享内存
int shmid=shmget((key_t)SHMKEYP, MAXNUM*sizeof(struct st_procinfo), 0666|IPC_CREAT);
if(shmid==-1)
{
logfile.write("shmget failed.");
}
//将共享内存连接到进程空间
struct st_procinfo *st_info=(struct st_procinfo *)shmat(shmid,0,0);
if(st_info==(void *)-1)
{
logfile.write("shmat failed.");
}
//检查共享内存的进程是否超时
for(int i=0;i<MAXNUM;i++)
{
if(st_info[i].pid>0)
{
logfile.write("checkproc pid=%d,name=%s,timeout=%d,atime=%d",st_info[i].pid,st_info[i].name,st_info[i].timeout,st_info[i].atime); //主要用于测试
time_t now_time=time(NULL);
if(st_info[i].timeout<=now_time-st_info[i].atime)
{
logfile.write("%d号进程超时,终止。",st_info[i].pid);
kill(st_info[i].pid,15);
}
}
}
//断开共享内存的连接
shmdt(st_info);
return 0;
}
代码的进一步优化
上面我们只是完成了一个简单的进程守护模块,但是其实不足之处还是比较多的,接下来我们可以看看我们还可以如何来优化一下这个代码,其实主要还是对检查共享内存的进程是否超时的代码逻辑进行一个优化,我们可以根据这个流程图来看一下我们有哪些地方没有考虑到:
根据上面的流程,我们可以得到改进后的代码:
//检查共享内存的进程是否超时
for(int i=0;i<MAXNUM;i++)
{
if(st_info[i].pid==0) continue;
if(st_info[i].pid>0)
{
//logfile.write("checkproc pid=%d,name=%s,timeout=%d,atime=%d",st_info[i].pid,st_info[i].name,st_info[i].timeout,st_info[i].atime); //主要用于测试
//向该进程发送信号0,测试进程是否存在
int iret=kill(st_info[i].pid,0);
if(iret==-1)
{
//进程不存在,在共享内存中删除该进程的记录
memset(&st_info[i],0,sizeof(struct st_procinfo));
continue;
}
//尝试检查进程是否超时
time_t now_time=time(0);
if(now_time-st_info[i].atime<st_info[i].timeout) continue;
logfile.write("进程%d超时,准备终止",st_info[i].pid);
struct st_procinfo tmp=st_info[i]; //备份进程信息
kill(tmp.pid,15); //首先尝试正常终止进程
for(int j=0;j<5;j++)
{
int iret=kill(tmp.pid,0);
if(iret==-1)
{
logfile.write("进程%d正常终止成功",tmp.pid);
continue; //进程不存在,说明已经正常终止;
}
sleep(1); //等待1秒
}
//进程仍然存在,说明进程没有正常终止,强制终止
kill(tmp.pid,9);
memset(&st_info[i],0,sizeof(struct st_procinfo));
logfile.write("进程%d强制终止成功",tmp.pid);
}
}
拓展:这里有一个问题,为什么这里我们要 写struct st_procinfo tmp=st_info[i]; //备份进程信息,主要是因为在
for(int j=0;j<5;j++)
{
int iret=kill(tmp.pid,0);
if(iret==-1)
{
logfile.write("进程%d正常终止成功",tmp.pid);
continue; //进程不存在,说明已经正常终止;
}
sleep(1); //等待1秒
}
如果在这段代码执行间隔中进程被终止,信息清零,那么后面的kill -0和kill -9都是发给它自己,会造成守护模块被kill -9自己杀死自己的乌龙
结语
以上就是一个简单的守护模块的全部实现细节,下篇见!
进程的心跳
什么是进程的心跳
在我们日常后台服务程序运行中,一般是调度模块,进程心跳以及进程监控共同工作,进而实现实现服务的稳定运行,在前面我们介绍过如何去实现一个简单的调度模块,而今天我们所要介绍的就是如何实现进程的心跳,首先什么是进程的心跳呢?进程的心跳机制是一种监控进程健康状况的方法,通常用于服务端应用或者需要长期运行的后台守护进程(daemon,我们在后台服务程序在运行中由于有很多功能需要运行,所以一般是以多进程的方式来同时运行多个后台服务程序,那么问题来了,当有多个后台服务程序在运行时我们如何来确定它们的运行状态呢?这就是进程心跳的功能了,进程心跳,顾名思义,就是我们用来判断进程是否正常运行的一种手段,我们首先定义一个心跳信息结构体,如下:
struct stprocinfo //存储进程心跳信息的结构体
{
int pid; //进程编号
char name[50]={0}; //进程名称
int timeout; //超时时间
time_t atime; //最后一次心跳时间
stprocinfo() =default; //默认构造函数
stprocinfo(int pid,char* name,int timeout,time_t atime):pid(pid),timeout(timeout),atime(atime)
{
strcpy(this->name,name);
}
};
结构体中存储了进程的相关信息,同时我们会通过atime和timeout来判断结构体是否是正常运行,下面我们来看一下具体的实现过程。
进程心跳的初步实现
 上面是一个进程心跳的初步实现,主要是以下几步:
上面是一个进程心跳的初步实现,主要是以下几步:
- 创建共享内存
//创建共享内存
shmid=shmget((key_t)0X5550,sizeof(struct stprocinfo)*1000,IPC_CREAT|0666);
if (shmid==-1)
{
perror("创建共享内存失败");
return -1;
}
cout<<"shmid="<<shmid<<endl;
- 将共享内存连接到当前进程的地址空间
//将共享内存连接到当前进程的地址空间
m_shm=(stprocinfo*)shmat(shmid,nullptr,0);
if(m_shm==(void*)-1)
{
perror("共享内存连接失败");
return -1;
}
cout<<"shmat ok"<<endl;
- 遍历共享内存,寻找空闲位置
//遍历当前共享内存的占用情况,主要用来调试
for(int i=0;i<1000;i++)
{
if(m_shm[i].pid!=0)
{
cout<<"pid="<<m_shm[i].pid<<" "
<<"name="<<m_shm[i].name<<" "
<<"timeout="<<m_shm[i].timeout<<" "
<<"atime="<<m_shm[i].atime<<endl;
}
}
stprocinfo info(getpid(),"server1",30,time(0));
//在共享内存中查找是否有空闲的地址
for(int i=0;i<1000;i++)
{
if(m_shm[i].pid==0)
{
m_pos=i;
cout<<"找到空闲地址,m_pos="<<m_pos<<endl;
break;
}
}
if(m_pos==-1)
{
cout<<"共享内存已满"<<endl;
Exit(-1);
}
memcp
- 程序运行并且更新进程心跳
while(1)
{
//写入程序的运行逻辑
sleep(10); //模拟程序运行
m_shm[m_pos].atime=time(0); //更新当前进程的心跳时间
}
完整代码如下:
#include "../../public/_public.h"
using namespace idc; //自己封装的命名空间
struct stprocinfo //存储进程心跳信息的结构体
{
int pid; //进程编号
char name[50]={0}; //进程名称
int timeout; //超时时间
time_t atime; //最后一次心跳时间
stprocinfo() =default; //默认构造函数
stprocinfo(int pid,char* name,int timeout,time_t atime):pid(pid),timeout(timeout),atime(atime)
{
strcpy(this->name,name);
}
};
int shmid=-1; //共享内存的ID
stprocinfo* m_shm=nullptr;//指向共享内存的地址
int m_pos=-1; //记录当前进程在共享内存的位置
void Exit(int sig); //信号处理函数
int main()
{
//信号处理
signal(SIGINT,Exit);
signal(SIGTERM,Exit);
//创建共享内存
shmid=shmget((key_t)0X5550,sizeof(struct stprocinfo)*1000,IPC_CREAT|0666);
if (shmid==-1)
{
perror("创建共享内存失败");
return -1;
}
cout<<"shmid="<<shmid<<endl;
//将共享内存连接到当前进程的地址空间
m_shm=(stprocinfo*)shmat(shmid,nullptr,0);
if(m_shm==(void*)-1)
{
perror("共享内存连接失败");
return -1;
}
cout<<"shmat ok"<<endl;
//遍历当前共享内存的占用情况,主要用来调试
for(int i=0;i<1000;i++)
{
if(m_shm[i].pid!=0)
{
cout<<"pid="<<m_shm[i].pid<<" "
<<"name="<<m_shm[i].name<<" "
<<"timeout="<<m_shm[i].timeout<<" "
<<"atime="<<m_shm[i].atime<<endl;
}
}
stprocinfo info(getpid(),"server1",30,time(0));
//在共享内存中查找是否有空闲的地址
for(int i=0;i<1000;i++)
{
if(m_shm[i].pid==0)
{
m_pos=i;
cout<<"找到空闲地址,m_pos="<<m_pos<<endl;
break;
}
}
if(m_pos==-1)
{
cout<<"共享内存已满"<<endl;
Exit(-1);
}
memcpy(&m_shm[m_pos],&info,sizeof(struct stprocinfo)); //将当前进程的心跳信息存入共享内存
while(1)
{
//写入程序的运行逻辑
sleep(10); //模拟程序运行
m_shm[m_pos].atime=time(0); //更新当前进程的心跳时间
}
return 0;
}
void Exit(int sig)
{
cout<<"收到信号:"<<sig<<endl;
//清除共享内存中的心跳信息结构体
if(m_pos!=-1)
{
memset(m_shm+m_pos,0,sizeof(struct stprocinfo));
m_pos=-1;
}
//将共享内存分离出来
if(m_shm!=nullptr)
{
shmdt(m_shm);
}
exit(0);
}
编译代码如下:
# 开发框架头文件路径
PUBINCL = -I/root/mylib/project/public
# 开发框架cpp文件名,这里直接包含进来,没有采用链接库,是为了方便调试。
PUBLICPP = /root/mylib/project/public/_public.cpp
# 编译参数
CFLAGS= -g
all: demo1
demo1:demo1.cpp
g++ $(CFLAGS) -o demo1 demo1.cpp $(PUBLICPP)
clean:
rm -f demo1
注明 以上仅供参考,大家根据自己的需求来进行修改。
测试并且运行,这里我们开启三个命令行来测试:


 我们看到基本实现了我们想的功能,将带有进程心跳的信息储存到了结构体中,后面我们会介绍我们如何基于守护进程来对进程的心跳来实现对进程状态的监控,不过这是后话了。
我们看到基本实现了我们想的功能,将带有进程心跳的信息储存到了结构体中,后面我们会介绍我们如何基于守护进程来对进程的心跳来实现对进程状态的监控,不过这是后话了。
进程心跳代码的优化
上面我们已经实现了一个简单的进程心跳代码,但是现在有几个实际情况需要我们来考虑,分别是:
- 这里我们关于退出信号的处理是无法处理
kill -9这种异常退出的,这个时候我们的Exit函数是无法正常发挥功能的,同时也会导致该进程的心跳信息残留在共享内存中,所以我们要对代码进行优化:
//在共享内存中查找是否有空闲的地址
for(int i=0;i<1000;i++) //如果有与该进程pid相同,说明有进程未清理干净
{
if(m_shm[i].pid==info.pid)
{
cout<<"找到旧进程"<<endl;
m_pos=i;
break;
}
}
if(m_pos==-1)
{
for(int i=0;i<1000;i++)
{
if(m_shm[i].pid==0)
{
m_pos=i;
cout<<"找到空闲地址,m_pos="<<m_pos<<endl;
break;
}
}
}
if(m_pos==-1)
{
cout<<"共享内存已满"<<endl;
Exit(-1);
}
- 这里我们要求的使用场景是多个进程在同时运行,那么问题来了,如果同时多个程序运行同时向共享内存的一块地址写怎么办?这里我们可以基于进程同步来解决这个问题,而向实现进程同步,就需要信号量了,这里我使用的是已经封装好的信号量,代码如下:
class csemp
{
private:
union semun // 用于操控共享内存的联合体
{
int value;
struct semid_ds *buf;
unsigned short *arry;
};
int m_semid; // 信号量id
/*如果将m_semflg设为SEM_UNOD,操作系统将跟踪进程对信号量的修改,在全部修改过信号量的进程终止后将信号量设置为初始值
m_semflag=1时用于互斥锁,m_semflag=0时用于生产消费者模型*/
short m_semflg; // 信号量值
csemp(const csemp &) = delete; // 禁用拷贝构造函数
csemp &operator=(const csemp &) = delete; // 禁用赋值运算符
public:
csemp() : m_semid(-1) {}
/*如果信号量已存在,就获取信号量
如果信号量不存在,就创建信号量并将其初始化为value
互斥锁时,value=1,semflag=SEM_UNOD
生产消费者模型时,value=0,semflag=0*/
bool init(key_t key, unsigned short value = 1, short semflg = SEM_UNDO);
bool wait(short value = -1); // P操作
bool post(short value = 1); // V操作
int getvalue();
bool destroy();
~csemp();
};
bool csemp::init(key_t key, unsigned short value, short semflg)
{
if (m_semid != -1) // 信号量已经初始化了
{
return false;
}
m_semflg = semflg;
if ((m_semid = semget(key, 1, 0666)) == -1) // 尝试获取信号量
{
if (errno == ENOENT) // 未找到信号量
{
if ((m_semid = semget(key, 1, IPC_CREAT | 0666 | IPC_EXCL)) == -1) // 创建信号量
{
if (errno == EEXIST) // 信号量已存在
{
if ((m_semid = semget(key, 1, 0666)) == -1)
{
perror("init semget 1");
return false;
}
return true;
}
else
{
perror("init semget 2");
return false;
}
}
union semun b;
b.value = value;
if (semctl(m_semid, 0, SETVAL, b) == -1) // 设置信号量初值
{
perror("init semctl");
return false;
}
}
else
{
perror("init semget 3");
return false;
}
}
return true;
}
bool csemp::wait(short value)
{
if (m_semid == -1)
return false;
struct sembuf s;
s.sem_num = 0;
s.sem_op = value;
s.sem_flg = m_semflg;
if (semop(m_semid, &s, 1) == -1)
{
perror("wait semop");
return false;
}
return true;
}
bool csemp::post(short value)
{
if (m_semid == -1)
return false;
struct sembuf s;
s.sem_num = 0;
s.sem_op = value;
s.sem_flg = m_semflg;
if (semop(m_semid, &s, 1) == -1)
{
perror("post semop");
return false;
}
return true;
}
int csemp::getvalue()
{
return semctl(m_semid, 0, GETVAL);
}
bool csemp::destroy()
{
if (m_semid == -1)
return false;
if (semctl(m_semid, 0, IPC_RMID) == -1)
{
perror("destroy semctl");
return false;
}
return true;
}
csemp::~csemp()
{
}
实现代码如下:
csemp shmlock;
if(shmlock.init(0x5550)==-1)
{
cout<<"shmlock init error"<<endl;
Exit(-1);
}
shmlock.wait(); //加锁
//在共享内存中查找是否有空闲的地址
for(int i=0;i<1000;i++)
{
if(m_shm[i].pid==info.pid)
{
cout<<"找到旧进程"<<endl;
m_pos=i;
break;
}
}
if(m_pos==-1)
{
for(int i=0;i<1000;i++)
{
if(m_shm[i].pid==0)
{
m_pos=i;
cout<<"找到空闲地址,m_pos="<<m_pos<<endl;
break;
}
}
}
if(m_pos==-1)
{
cout<<"共享内存已满"<<endl;
shmlock.post(); //解锁
Exit(-1);
}
memcpy(&m_shm[m_pos],&info,sizeof(struct stprocinfo)); //将当前进程的心跳信息存入共享内存
shmlock.post(); //解锁
最后我们就实现一个基本的可以实现多进程监控的进程心跳程序了,在最后我们可以将它封装成一个简单的类,供我们以后使用:
// 进程心跳有关的类
struct st_procinfo // 存储进程心跳信息的结构体
{
int pid; // 进程编号
char name[50] = {0}; // 进程名称
int timeout; // 超时时间
time_t atime; // 最后一次心跳时间
st_procinfo() = default; // 默认构造函数
st_procinfo(int pid, char *name, int timeout, time_t atime) : pid(pid), timeout(timeout), atime(atime)
{
strcpy(this->name, name);
}
};
#define MAXNUM 1000; // 最大进程数
#define SHMKEYP 0x5095 // 共享内存的key。
#define SEMKEYP 0x5095 // 信号量的key。
class cpactive // 实现进程心跳的类
{
private:
int shmid;
int m_pos;
st_procinfo *m_shm;
public:
cpactive();
bool init(int timeout,string pname="",clogfile *logfile=nullptr); //这里传指针视为了选择是否使用日志打印
bool update(); //更新心跳时间
~cpactive();
};
cpactive::cpactive()
{
m_shmid=0;
m_pos=-1;
m_shm=0;
}
// 把当前进程的信息加入共享内存进程组中。
bool cpactive::addpinfo(const int timeout,const string &pname,clogfile *logfile)
{
if (m_pos!=-1) return true;
// 创建/获取共享内存,键值为SHMKEYP,大小为MAXNUMP个st_procinfo结构体的大小。
if ( (m_shmid = shmget((key_t)SHMKEYP, MAXNUMP*sizeof(struct st_procinfo), 0666|IPC_CREAT)) == -1)
{
if (logfile!=nullptr) logfile->write("创建/获取共享内存(%x)失败。\n",SHMKEYP);
else printf("创建/获取共享内存(%x)失败。\n",SHMKEYP);
return false;
}
// 将共享内存连接到当前进程的地址空间。
m_shm=(struct st_procinfo *)shmat(m_shmid, 0, 0);
/*
struct st_procinfo stprocinfo; // 当前进程心跳信息的结构体。
memset(&stprocinfo,0,sizeof(stprocinfo));
stprocinfo.pid=getpid(); // 当前进程号。
stprocinfo.timeout=timeout; // 超时时间。
stprocinfo.atime=time(0); // 当前时间。
strncpy(stprocinfo.pname,pname.c_str(),50); // 进程名。
*/
st_procinfo stprocinfo(getpid(),pname.c_str(),timeout,time(0)); // 当前进程心跳信息的结构体。
// 进程id是循环使用的,如果曾经有一个进程异常退出,没有清理自己的心跳信息,
// 它的进程信息将残留在共享内存中,不巧的是,如果当前进程重用了它的id,
// 守护进程检查到残留进程的信息时,会向进程id发送退出信号,将误杀当前进程。
// 所以,如果共享内存中已存在当前进程编号,一定是其它进程残留的信息,当前进程应该重用这个位置。
for (int ii=0;ii<MAXNUMP;ii++)
{
if ( (m_shm+ii)->pid==stprocinfo.pid ) { m_pos=ii; break; }
}
csemp semp; // 用于给共享内存加锁的信号量id。
if (semp.init(SEMKEYP) == false) // 初始化信号量。
{
if (logfile!=nullptr) logfile->write("创建/获取信号量(%x)失败。\n",SEMKEYP);
else printf("创建/获取信号量(%x)失败。\n",SEMKEYP);
return false;
}
semp.wait(); // 给共享内存上锁。
// 如果m_pos==-1,表示共享内存的进程组中不存在当前进程编号,那就找一个空位置。
if (m_pos==-1)
{
for (int ii=0;ii<MAXNUMP;ii++)
if ( (m_shm+ii)->pid==0 ) { m_pos=ii; break; }
}
// 如果m_pos==-1,表示没找到空位置,说明共享内存的空间已用完。
if (m_pos==-1)
{
if (logfile!=0) logfile->write("共享内存空间已用完。\n");
else printf("共享内存空间已用完。\n");
semp.post(); // 解锁。
return false;
}
// 把当前进程的心跳信息存入共享内存的进程组中。
memcpy(m_shm+m_pos,&stprocinfo,sizeof(struct st_procinfo));
semp.post(); // 解锁。
return true;
}
// 更新共享内存进程组中当前进程的心跳时间。
bool cpactive::uptatime()
{
if (m_pos==-1) return false;
(m_shm+m_pos)->atime=time(0);
return true;
}
cpactive::~cpactive()
{
// 把当前进程从共享内存的进程组中移去。
if (m_pos!=-1) memset(m_shm+m_pos,0,sizeof(struct st_procinfo));
// 把共享内存从当前进程中分离。
if (m_shm!=0) shmdt(m_shm);
}
至此一个简单的进程心跳类就封装号了,后面我会介绍如何基于守护进程,进程心跳和调度模块来实现对进程的监控,大家下篇见!
基于socket套接字的网络编程
客户端类的编写
客户端通讯的过程
客户端连接的过程其实很好理解,主要就是以下几步:
- 创建客户端socket
- 基于客户端socket和服务端ip以及服务端开放的通讯端口与服务端建立连接
- 读取/发送数据
- 关闭socket,断开连接 而我们的对客户端类的编写,也是基于上面的几步过程来展开的。
客户端的私有成员
在上面我们提到了客户端连接服务端所需的一些信息,例如客户端socket,服务端ip以及服务端开放的通讯端口(云服务器开放通讯端口需要设置安全组),所以我们可以这样定义客户端类:
private:
int m_socket; // 客户端的socket
unsigned int server_port;// 服务端的端口
string server_ip; //服务端的ip
客户端的公共函数
我们上面说过客户端连接服务端以及相关工作的大致流程,所以在定义客户端类的函数时,大概是以下类型的函数:
public:
ctcpclient(){m_socket=-1;}
bool Connect(const unsigned int port,const string& ip); //客户端连接服务端
bool Read(string& buff,const int itimeout=0); //接收文本数据
bool Read(void* buff,const int bufflen,const int itimeout=0); //接收二进制数据
bool Write(const string& buff); //发送文本数据
bool Write(const void* buff,const int bufflen); //发送二进制数据
void Close(); //关闭连接
~ctcpclient(){Close();}
这里的构造函数与析构函数无需多言,接下来我们主要对相关的工作函数进行探究。
Connect(客户端连接)函数
在讲解Connect函数之前我们先来看一下它的具体执行的逻辑:
bool ctcpclient::Connect(const unsigned int port, const string &ip)
{
if (m_socket != -1)
{
Close();
}
// 忽略SIGPIPE信号,防止程序异常退出。
// 如果send到一个disconnected socket上,内核就会发出SIGPIPE信号。这个信号
// 的缺省处理方法是终止进程,大多数时候这都不是我们期望的。我们重新定义这
// 个信号的处理方法,大多数情况是直接屏蔽它。
signal(SIGPIPE, SIG_IGN);
server_port = port;
server_ip = ip;
m_socket = socket(AF_INET, SOCK_STREAM, 0);
if (m_socket < 0)
{
return false;
}
struct sockaddr_in server_addr;
struct hostent *h;
memset(&server_addr, 0, sizeof(server_addr));
if ((h = gethostbyname(ip.c_str())) == NULL)
{
Close();
return false;
}
server_addr.sin_family = AF_INET;//指定通讯协议
server_addr.sin_port = htons(server_port); //指定通讯端口
memset(h, 0, sizeof(h));
memcpy(h->h_addr, &server_ip[0], server_ip.length()); //指定通讯IP地址
if (connect(m_socket, (struct sockaddr *)&server_addr, sizeof(server_addr)) != 0)
{
return false;
}
return true;
}
上述主要经过了一下几个步骤:
- 检查socket,查看当前客户端是否处于未连接状态
- 设置相关信号的处理方式,防止异常情况的出现
- 初始化客户端socket
- 定义
server_addr与struct hostent *h结构体配置相关信息 - 与客户端建立连接
Read(接收)函数
Read函数在这里所起到的作用主要是接收数据的作用,接下来我们将从接收数据的不同作为开始来探究其中的细节。
接收文本数据
在对相关函数的执行逻辑与细节进行讲解之前,我们先来看一下相关的函数签名与函数实现:
bool Read(string& buff,const int itimeout=0); //接收文本数据
bool tcpread(const int sockfd,string &buffer,const int itimeout=0); // 读取文本数据
bool readn(const int sockfd, char *buffer, const size_t n);
bool ctcpclient::Read(string &buff, const int itimeout)
{
if (m_socket < 0)
{
return false;
}
return (tcpread(m_socket, buff, itimeout));
}
bool tcpread(const int sock, string &buff, const int itimeout)
{
if (sock < 0)
{
return false;
}
if (itimeout > 0)
{
struct pollfd fds;
fds.fd = sock;
fds.events = POLLIN;
int ret = poll(&fds, 1, itimeout * 1000);
if (ret < 0)
{
return false;
}
if (ret == 0)
{
return false;
}
}
if (itimeout < -1)
{
struct pollfd fds;
fds.fd = sock;
fds.events = POLLIN;
int ret = poll(&fds, 1, 0);
if (ret < 0)
{
return false;
}
if (ret == 0)
{
return false;
}
}
int bufflen = 0;
if (readn(sock, (char *)&bufflen, 4) == false) // 读取报文长度
{
return false;
}
buff.resize(bufflen);
if (readn(sock, &buff[0], bufflen) == false) // 读取报文内容
{
return false;
}
return true;
}
bool readn(const int sockfd, char *buffer, const size_t n)
{
int nleft = n; // 剩余需要读取的字节数。
int idx = 0; // 已成功读取的字节数。
int nread; // 每次调用recv()函数读到的字节数。
while (nleft > 0)
{
if ((nread = recv(sockfd, buffer + idx, nleft, 0)) <= 0)
return false;
idx = idx + nread;
nleft = nleft - nread;
}
return true;
}
我们可以看到上面有关于数据接收的函数一共有三个,这里主要是客户端与服务端接收/发送数据的方式基本一致,所以我们选择对相关函数进行封装避免多次书写重复函数使代码编的臃肿,下面来给大家解释主要函数的作用:
tcpread我们知道端到端的通讯其实不是每次都是立即进行的,所以接收数据的一方有时候要等待发送数据的一方将数据发送过来,而这里我们基于poll实现了一个超时机制,让我们可以手动设置接收数据方是否等待以及等待的最大时长readn这个主要是实现对数据的读写,相对于直接调用recv函数,每次从socket读取指定数量的字节,即使recv函数不能一次读取所有字节。通过在循环中跟踪剩余需要读取的字节数,可以确保读取完整的数据,进而避免因为recv函数每次读取的字节数不固定而导致的数据读取不完整或错误。
二进制数据
二进制数数接收与文本数据的接收又有所不同,我们来看一下它的函数签名与具体逻辑:
- 函数签名
bool Read(void* buff,const int bufflen,const int itimeout=0); //接收二进制数据
bool tcpread(const int sockfd, void *buffer, const int ibuflen, const int itimeout = 0);//接收二进制数据
bool readn(const int sockfd, char *buffer, const size_t n);
- 函数逻辑
bool ctcpclient::Read(void *buff, const int bufflen, const int itimeout)
{
if (m_socket < 0)
{
return false;
}
return (tcpread(m_socket, buff, bufflen, itimeout));
}
bool tcpread(int sock, void *buff, const int bufflen, const int itimeout)
{
if (sock < 0)
{
return false;
}
if (itimeout > 0)
{
struct pollfd fds;
fds.fd = sock;
fds.events = POLLIN;
int ret = poll(&fds, 1, itimeout * 1000);
if (ret <= 0)
{
return false;
}
}
if (itimeout < -1)
{
struct pollfd fds;
fds.fd = sock;
fds.events = POLLIN;
int ret = poll(&fds, 1, 0);
if (ret <= 0)
{
return false;
}
}
if (readn(sock, (char *)buff, bufflen) == false) // 读取报文内容
{
return false;
}
return true;
}
bool readn(const int sockfd, char *buffer, const size_t n)
{
int nleft = n; // 剩余需要读取的字节数。
int idx = 0; // 已成功读取的字节数。
int nread; // 每次调用recv()函数读到的字节数。
while (nleft > 0)
{
if ((nread = recv(sockfd, buffer + idx, nleft, 0)) <= 0)
return false;
idx = idx + nread;
nleft = nleft - nread;
}
return true;
}
我们可以发现二进制数据的接收与文本数据相比有所不同,相对于文本数据,二进制数据减少了一个接收数据长度的过程,这是因为我们在接收/二进制数据时,二进制数据通常会包含自身的大小信息。在通信双方约定好数据格式之后,发送方会在发送数据时先将数据的大小信息编码到数据中,接收方在接收数据时可以直接根据数据的大小信息来确定整个报文的大小,从而正确地解析和处理数据。
Write函数
write函数的细节与read函数类似,这里不做赘述,直接看函数签名与逻辑了:
- 函数签名
bool Write(const string& buff); //发送文本数据
bool Write(const void* buff,const int bufflen); //发送二进制数据
bool tcpwrite(const int sockfd, const void *buffer, const int ibuflen);//发送二进制数据
bool tcpwrite(const int sockfd, const string &buffer); //发送文本数据
bool readn(const int sockfd, char *buffer, const size_t n);
- 函数逻辑
bool ctcpclient::Write(const string &buff)
{
if (m_socket < 0)
{
return false;
}
return (tcpwrite(m_socket, buff));
}
bool ctcpclient::Write(const void *buff, const int bufflen)
{
if (m_socket < 0)
{
return false;
}
return (tcpwrite(m_socket, (char *)buff, bufflen));
}
bool tcpwrite(const int sock, const string &buff)
{
if (sock < 0)
{
return false;
}
int bufflen = buff.length();
if (writen(sock, (char *)&bufflen, 4) == false) // 发送报文长度
{
return false;
}
if (writen(sock, &buff[0], bufflen) == false) // 发送报文内容
{
return false;
}
return true;
}
bool tcpwrite(int sock, const void *buff, const int bufflen)
{
if (sock < 0)
{
return false;
}
if (writen(sock, (char *)buff, bufflen) == false) // 发送报文内容
{
return false;
}
return true;
}
bool writen(const int sockfd, const char *buffer, const size_t n)
{
int nleft = n; // 剩余需要写入的字节数。
int idx = 0; // 已成功写入的字节数。
int nwritten; // 每次调用send()函数写入的字节数。
while (nleft > 0)
{
if ((nwritten = send(sockfd, buffer + idx, nleft, 0)) <= 0)
return false;
nleft = nleft - nwritten;
idx = idx + nwritten;
}
return true;
}
Close函数
Close函数主要用来关闭已经打开的socket
void ctcpclient::Close()
{
if (m_socket > 0)
{
close(m_socket);
m_socket = -1;
}
}
服务端类的编写
服务端类的工作流程
- 初始化监听socket,指定端口与ip,将socket设置为监听状态
- 从等待连接的队列中选取一个客户端进行连接
- 发送/接收数据
- 关闭socket,断开连接
服务端类的成员
class ctcpserver
{
private:
int m_listensock;//服务端的监听socket
int m_connsock; //已连接的客户端socket
int sockaddr_len;//客户端地址的长度
struct sockaddr_in server_addr;//服务端地址
struct sockaddr_in client_addr;//客户端地址
public:
ctcpserver(){m_listensock=-1;m_connsock=-1;}
bool Initserver(const unsigned int port,const int backlog=5);//初始化服务端
bool Accept(); //从已连接队列中获取一个客户端连接
bool Read(string& buff,const int itimeout=0); //接收文本数据
bool Read(void* buff,const int bufflen,const int itimeout=0); //接收二进制数据
bool Write(const string& buff); //发送文本数据
bool Write(const void* buff,const int bufflen); //发送二进制数据
char* getclientip(); //获取客户端的ip
void Closelisten(); //关闭监听socket
void Closeconn(); //关闭已连接的客户端socket
~ctcpserver(){Closeconn();Closelisten();}
};
Initserver函数
在讲解前我们来看一下函数的具体逻辑:
bool ctcpserver::Initserver(const unsigned int port, const int backlog) // backlog:等待连接队列的最大长度
{
if (m_listensock != -1)
{
Closelisten();
}
signal(SIGPIPE, SIG_IGN);
// 打开SO_REUSEADDR选项,当服务端连接处于TIME_WAIT状态时可以再次启动服务器,
// 否则bind()可能会不成功,报:Address already in use。
int opt = 1;
setsockopt(m_listensock, SOL_SOCKET, SO_REUSEADDR, &opt, sizeof(opt));
m_listensock = socket(AF_INET, SOCK_STREAM, 0);
if (m_listensock < 0)
{
return false;
}
memset(&server_addr, 0, sizeof(server_addr));
server_addr.sin_family = AF_INET;
m_listensock = socket(AF_INET, SOCK_STREAM, 0);
if (m_listensock < 0)
{
return false;
}
struct sockaddr_in server_addr;
memset(&server_addr, 0, sizeof(server_addr));
server_addr.sin_family = AF_INET;
server_addr.sin_addr.s_addr = htonl(INADDR_ANY);
server_addr.sin_port = htons(port);
if (bind(m_listensock, (struct sockaddr *)&server_addr, sizeof(server_addr)) != 0)
{
Closelisten();
return false;
}
if (listen(m_listensock, backlog) != 0)
{
Closelisten();
return false;
}
return true;
}
我们梳理一下它这个的工作流程;
- 检查服务端是否已经被初始化
- 设置相关信号的处理方式,防止异常情况的出现
- 初始化服务端的监听socket
- 设置相关参数,并指定其为用于通信的ip与端口(bind)
- 将socket设置为监听状态
Accept函数
一个时间段可能会有多个客户端连接服务端,这时候就形成了一个等待队列,服务单会在这个等待队列里面利用accept函数选取一个客户端进行连接:
bool ctcpserver::Accept()
{
if (m_listensock < 0)
{
return false;
}
sockaddr_len = sizeof(struct sockaddr_in);
if ((m_connsock = accept(m_listensock, (sockaddr *)&client_addr, (socklen_t *)&sockaddr_len)) < 0)
{
return false;
}
return true;
}
Read与Write函数
服务端接收与发送数据与客户端基本功一致,这里就不做赘述,基本的这一点什么都已经提出来了,我们直接看代码:
bool ctcpserver::Read(string &buff, const int itimeout)
{
if (m_listensock < 0)
{
return false;
}
return (tcpread(m_connsock, buff, itimeout));
}
bool ctcpserver::Read(void *buff, const int bufflen, const int itimeout)
{
if (m_listensock < 0)
{
return false;
}
return (tcpread(m_connsock, buff, bufflen, itimeout));
}
bool ctcpserver::Write(const string &buff)
{
if (m_listensock < 0)
{
return false;
}
return (tcpwrite(m_connsock, buff));
}
bool ctcpserver::Write(const void *buff, const int bufflen)
{
if (m_listensock < 0)
{
return false;
}
return (tcpwrite(m_connsock, (char *)buff, bufflen));
}
getclientip()函数
该函数主要的作用是获取连接的客户端的ip:
char *ctcpserver::getclientip()
{
return inet_ntoa(client_addr.sin_addr);
}
Close函数
void ctcpserver::Closelisten()
{
if (m_listensock > 0)
{
close(m_listensock);
m_listensock = -1;
}
}
void ctcpserver::Closeconn()
{
if (m_connsock > 0)
{
close(m_connsock);
m_connsock = -1;
}
}
结语
Cpp不同于其他语言,像Go,Python等语言对上述的细节其实已经封装好了,但是cpp则是需要我们去一点点的实现,为了避免重复的书写代码,我们可以将它们封装成类来供我们去使用,以上就是这篇文章的全部内容了,大家下篇见!
IO多路复用 —— select
什么是IO多路复用
前言
我们在Linux上服务端一般是要同时连接多个客户端进行通信,但是为每一个客户端连接创建一个进/线程,会消耗很多资源,一个1核2GB的虚拟机,大概只能创建100多个线程,但是我们经常使用网络知道,这样是远远不能满足我们日常的使用需求的,所以为了解决这一问题,就需要我们去使用IO多路复用。
IO多路复用
IO多路复用指的是我们可以使用一个进/线程去处理多个TCP链接,减少系统开销,而我们常见的IO多路复用主要用三种:
- select(1024)
- poll(几千)
- epoll(百万)
网络通讯中的读与写事件
读事件
- 已连接队列中有已经准备好的socket(有新的客户端连接上来)
- 接收缓存有数据可以读(对端发送的报文已经送达)
- tcp连接断开(对端使用close()函数断开了连接)
写事件
- 发送端缓冲区没有满,可以写入数据(向对端发送报文)
select模型
位图
-
什么是位图
select实现IO多路复用是基于位图来实现的,位图的本质是一个32位整型数组(int[32]),一个32位整型有4个字节,每个字节有8个位: $$ 3284=1024 $$ 每一个位可以监听一个socket这也是select模型课件监听1024个socket的原因所在。
-
位图的相关操作
在Linux内核中为我们提供相关的宏让我们操作位图:
void D_CLR(int fd,fd_set* set);//将socket从位图中删除 int FD_ISSET(int fd,fd_set *set);//判断socket是否在位图中 void FD_SET(int fd,fd_set* set);//将socket加入到位图中 void FD_ZERO(fd_set* set); //将位图全部初始化为0
select模型的细节
写事件
- 如果
tcp的发送缓冲区没有满,那么此时socket连接是可写的 - 一般来说发送缓冲区不容易填满,但是如果发送数据量过大或者网络带宽不够,发送缓冲区有填满的可能。
水平触发
- select()监视的socket如果发生了事件,select()会返回(通知应用程序处理事件),如果事件没有被处理,再次调用select()的时候会立即再通知
- 存在的问题
- 这里操作位图的方法是轮询,它的性能会随着socket的增多而降低
- 每次调用select,需要拷贝位图,而且select属于用户态,网络通信属于内核态,需要拷贝两次,会影响select的性能
- 受位图大小的限制,每个进/线程selectt所能处理的socket数量默认是1024个,性能不够高,无法处理网络通信频繁的实际场景
select模型监控socket通讯流程图
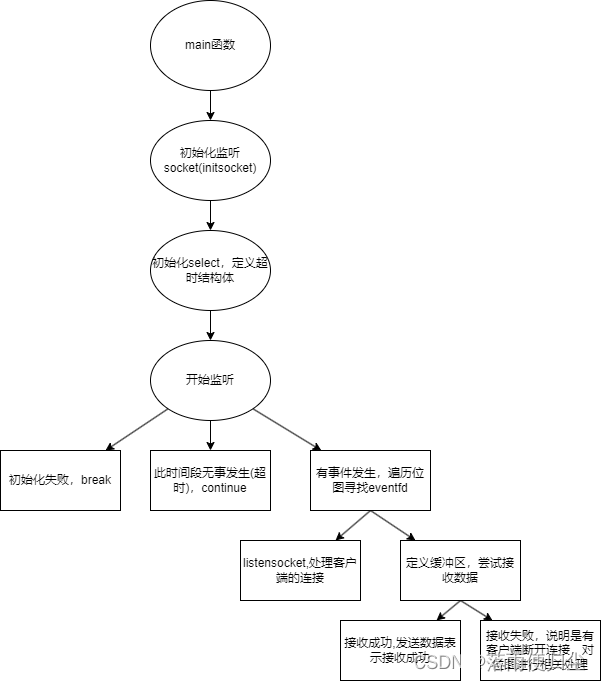
代码示例
#include "data-sharing-center/public/_cmpublic.h"
#include <string.h>
using namespace std;
int inintserver(int port); //初始化监听端口
int main(int argc,char* argv[])
{
if(argc!=2)
{
cout<<"using example:./server [port]"<<endl;
return -1;
}
//初始化服务端用来监听的socket
int listensock=inintsocket(atoi(argv[1]));
if(listensock<0)
{
perror("inintsocket() error");
return -1;
}
cout<<"listensock="<<listensock<<endl;
//初始化select
fd_set readfds;
FD_ZERO(&readfds);
FD_SET(listensock,&readfds);
int maxfd=listensock;//记录当前监听socket的数量
while(true) //使用select循环监听
{
//定义超时结构体
struct timeval timeout; //定义超时结构体
timeout.tv_sec=10; //秒
timeout.tv_usec=0; //微妙
fd_set tmps=readfds; //select操作中会对位图进行修改,创建一个临时位图
int infds=select(maxfd+1,&tmps,NULL,NULL,&timeout); //开启监听
if(infds<0) //连接失败
{
perror("select() error");
break;
}
else if(infds==0) //超时(此时间段没有事件发生)
{
cout<<"select timeout"<<endl;
continue;
}
else //有事件发生
{
//遍历位图,查看是哪一个socket发生事件
for(int eventfd=0;eventfd<=maxfd;eventfd++)
{
if(FD_ISSET(eventfd,&tmps)) //查看是否是该socket
{
if(eventfd=listensock) //如果是监听,说明发生的事件是有客户顿socket发送了连接请求
{
//接收客户端连接
struct sockaddr_in clientaddr;
socklen_t addrlen=sizeof(clientaddr);
int clientsock=accept(listensock,(struct sockaddr*)&clientaddr,&addrlen);
if(clientsock<0)
{
perror("accept() error");
continue;
}
cout<<"client connected,clientsock:"<<clientsock<<endl;
//将新的客户端socket加入位图
FD_SET(clientsock,&readfds);
if(clientsock>maxfd)
{
maxfd=clientsock;
}
}
else //否则就是客户端向服务端发送了数据,或者有客户端断开了连接
{
char buffer[1024]; //用来接收数据
memset(buffer,0,sizeof(buffer));
if(recv(eventfd,buffer,sizeof(buffer),0)<0) //说明是有客户端断开了
{
cout<<"client disconnected,clientfd="<<eventfd<<endl;
close(eventfd);
FD_CLR(eventfd,&tmps);
if(maxfd==eventfd); //重新计算maxfd的值,注意,只有当eventfd==maxfd时才需要计算。
{
for(int ii=maxfd;ii>0;ii--)
{
if(FD_ISSET(ii,&readfds))
{
maxfd=ii;
break;
}
}
}
}
else //说明是有客户端发送了数据
{
cout<<"client data:"<<buffer<<endl;
send(eventfd,buffer,strlen(buffer),0); //把数据发送回去说明已经收到了
}
}
}
}
}
}
return 0;
}
int inintsocket(int port)
{
int sock=socket(AF_INET,SOCK_STREAM,0);
if(sock<0)
{
perror("socket() error");
return -1;
}
//设置端口复用
int opt=1;
unsigned int len=sizeof(opt);
setsockopt(sock,SOL_SOCKET,SO_REUSEADDR,&opt,len);
//绑定端口
struct sockaddr_in serveraddr;
serveraddr.sin_family=AF_INET;
serveraddr.sin_port=htons(port);
serveraddr.sin_addr.s_addr=htonl(INADDR_ANY);
if(bind(sock,(struct sockaddr*)&serveraddr,sizeof(serveraddr))<0)
{
perror("bind() error");
close(sock);
return -1;
}
//监听
if(listen(sock,5)<0)
{
perror("listen() error");
close(sock);
return -1;
}
return sock;
}
注意: 这里的头文件是博主自己封装的,大家可以使用’man+函数名的方式查看相关函数所需的头文件。
IO多路复用 —— poll
poll模型
前言
poll模型与select的实现原理相近,所以绝大数的原理其实可以参考select,我们这里对二者的相同点不做过多探究,如果有需要可以去看一下博主的上一篇文章: 这里我们只对二者的不同处做说明。
poll结构体
在poll模型中,是利用pollfd结构体数组来储存socket通讯中使用的socket,pollfd的结构体实现如下:
struct pollfd
{
int fd; //存储的socket
short events; // socket触发的事件
short revents; // 返回的事件
}
由于poll使用的是结构体数组,所以相比于select,poll没有1024的数量限制。
poll模型存在的问题与一些细节
- 在程序中,poll'的数据结构是数组,传入内核里面切换为链表
- 每次调用select()需要拷贝两次bitmap,poll拷贝一次结构体数组
- poll监视的连接数没有1024的限制,但是随着socket的增多,poll的效率会降低
poll流程图(这里以服务端监听socket为例,只有只读事件)

代码示例
- poll.h
#include "data-sharing-center/public/_cmpublic.h"
int initsocket(int port);
- poll.cpp
#include "poll.h"
using namespace std;
int main(int argc,char* argv[])
{
if(argc!=2)
{
cout<<"using example:./server [port]"<<endl;
return -1;
}
int listensock=initsocket(atoi(argv[1]));
if(listensock<0)
{
perror("initsocket() error");
return -1;
}
//定义poll模型的结构体数组
struct pollfd fds[2048]; //这里写的数字仅说明可以超过1024,具体情况请根据实际情况来判断
//初始化结构体数组
for(int ii=0;ii<2048;ii++)
{
fds[ii].fd=-1;
fds[ii].events=POLLIN; //POLLIN:读,POLLOUT:写,POLLIN|POLLOUT:读写
}
int maxfd=listensock;
while(true)
{
//开始监听
int infds=poll(fds,maxfd+1,100); //最后的数字是超时机制所需的时间,单位为微秒
if(infds<0) //连接失败
{
perror("poll() error");
break;
}
else if(infds==0) //超时
{
cout<<"poll() timeout"<<endl;
continue;
}
else //有事件发生
{
for(int ii=0;ii<maxfd+1;ii++) //遍历结构体数组,寻找发生事件的socket
{
if(fds[ii].fd==-1) continue;
if((fds[ii].events&&POLLIN)==0) continue; //没有读事件
if(fds[ii].fd==listensock) // 有客户端发送了连接请求
{
struct sockaddr_in clientaddr;
socklen_t len=sizeof(clientaddr);
int clientsock=accept(listensock,(struct sockaddr*)&clientaddr,&len);
if(clientsock<0)
{
perror("accept() error");
break;
}
cout<<"new client connect"<<endl;
//将新的socket加入到结构体数组中
fds[maxfd].fd=clientsock;
fds[maxfd].events=POLLIN;
if(maxfd<clientsock) maxfd=clientsock;
}
else
{
//有客户端发送了数据
char buff[1024];
memset(buff,0,sizeof(buff));
int len=recv(fds[ii].fd,buff,sizeof(buff),0);
if(len<0) //说明是客户端关闭了连接
{
close(fds[ii].fd);
fds[ii].fd=-1;
fds[ii].events=0;
if(fds[ii].fd==maxfd)
{
for(int ii=maxfd;ii>0;ii--)
{
if(fds[ii].fd!=-1)
{
maxfd=ii;
break;
}
}
}
}
cout<<"recv data:"<<buff<<endl;
//将数据原封不动的发送给客户端
send(fds[ii].fd,buff,len,0);
}
}
}
}
return 0;
}
int inintsocket(int port)
{
int sock=socket(AF_INET,SOCK_STREAM,0);
if(sock<0)
{
perror("socket() error");
return -1;
}
//设置端口复用
int opt=1;
unsigned int len=sizeof(opt);
setsockopt(sock,SOL_SOCKET,SO_REUSEADDR,&opt,len);
//绑定端口
struct sockaddr_in serveraddr;
serveraddr.sin_family=AF_INET;
serveraddr.sin_port=htons(port);
serveraddr.sin_addr.s_addr=htonl(INADDR_ANY);
if(bind(sock,(struct sockaddr*)&serveraddr,sizeof(serveraddr))<0)
{
perror("bind() error");
close(sock);
return -1;
}
//监听
if(listen(sock,5)<0)
{
perror("listen() error");
close(sock);
return -1;
}
return sock;
}
注意: 这里的头文件是博主自己封装的,大家可以使用’man+函数名的方式查看相关函数所需的头文件以及其帮助文档,示例:


IO多路复用 —— epoll
前言
在之前我们就已经介绍过了select和poll,在作为io多路复用的最后一个的epoll,我们来总结一下它们之间的区别:
select
实现原理
select 通过一个文件描述符集合(fd_set)来工作,该集合可以包含需要监控的文件描述符。调用者会指定一个超时时间,如果在这个时间内没有任何描述符准备好,则函数返回。select 可以同时监听读、写和异常三种类型的事件。
优点
select 函数调用和实现比较简单,同时它支持跨平台
缺点
-
select是基于位图这一数据结构来存储与遍历文件描述符相关的信息,由于位图数据结构的限制,select最多能同时监听1024个文件描述符,如果超过1024个文件描述符,无法实现大规模的并发处理。
-
每次调用select,需要拷贝位图,而且select属于用户态,网络通信属于内核态,需要拷贝两次,会影响select的性能。
-
select的每次监听都需要遍历一整个位图,随着需要监听的socket增加,性能会大大下降。
poll
实现原理
poll 通过一个链表来存储需要监控的文件描述符,当文件描述符就绪时,链表中的节点会被移动到就绪链表中,当链表为空时,poll会阻塞。poll与select类似,也是通过一个文件描述符集合来工作,但是poll所使用的数据结构是一个结构体数组,它的结构如下:
struct pollfd
{
int fd; //存储的socket
short events; // socket触发的事件
short revents; // 返回的事件
}
优点
poll 函数调用和实现简单,同时它支持跨平台,同时相对于select,poll没有了1024的限制,可以实现对更多文件描述符的监听。
缺点
poll监视的连接数没有1024的限制,但是随着socket的增多,poll的效率会降低,无法处理超大规模并发。
epoll
epoll的原理
epoll 全名是 eventpoll,是Linux内核2.5.44 版本之后才出现的一个事件通知机制。它属于IO多路复用技术的一种形式,IO多路复用技术指的是一个操作里同时监听多个输入输出源,在其中一个或多个输入输出源可用的时候返回,然后对其进行读写操作。上面的select和poll都具有一个通病,那就是都有性能瓶颈,而epoll可以承受百万级别的连接,属于select和poll模式的升级版。
epoll的优点
-
select和poll监听都是线性检测的,而epoll是基于红黑树来管理文件描述符,对于事件的发生,它不像select和poll那样需要遍历整个文件描述符集合,而是通过回调函数来通知,所以epoll的效率更高.
-
select和poll在工作中需要对集合进行判断来看哪些文件描述符已经就绪,而epoll则不需要,epoll通过回调函数来通知,所以epoll的效率更高。
当我们需要监听大量的文件描述符时,epoll的效率会更高,所以epoll是当前最常用的IO多路复用技术。
epoll的操作函数
在Linux内核中,主要给我们提供了一下三个函数来操作epoll:
#include <sys/epoll.h>
//创建一个epoll实例,通过红黑树来管理文件描述符
int epoll_create(int size);
//管理红黑树中的文件描述符(添加,修改,删除)
int epoll_ctl(int epfd, int op, int fd, struct epoll_event *event);
//等待文件描述符就绪
int epoll_wait(int epfd, struct epoll_event *events, int maxevents, int timeout);
epoll_create
epoll_create函数用于创建一个epoll实例,参数size表示要监听的文件描述符的数量,但是这个参数在Linux 2.6.8之后已经没有意义了,因为epoll的红黑树可以动态扩展,所以大于0即可。
int epfd = epoll_create(0);
返回值:
- 成功:返回epoll实例的文件描述符
- 失败:返回-1,并设置errno
epoll_ctl
epoll_ctl函数用于管理红黑树中的文件描述符,参数epfd表示epoll实例的文件描述符,参数op表示要进行的操作,参数fd表示要监听的文件描述符,参数event表示要监听的事件。
在epoll中有以下和事件相关的数据结构
typedef union epoll_data {
void *ptr;
int fd; // 通常情况下使用这个成员, 和epoll_ctl的第三个参数相同即可
uint32_t u32;
uint64_t u64;
} epoll_data_t;
struct epoll_event {
uint32_t events; /* Epoll events */
epoll_data_t data; /* User data variable */
};
而在epool_ctl函数中主要要注意下面几个参数;
int epoll_ctl(int epfd,int op,int fd,struct epoll_event *event);
epfd:epoll实例的文件描述符op:要进行的操作EPOLL_CTL_ADD:添加文件描述符EPOLL_CTL_MOD:修改文件描述符EPOLL_CTL_DEL:删除文件描述符
fd:要监听的文件描述符event:epoll事件,用来修饰fd,指定检测什么事件events:事件类型EPOLLIN:读事件EPOLLOUT: 写事件EPOLLERR: 错误事件
-
data:用户数据,通常情况下使用fd即可
epoll_wait
epoll_wait函数用于等待事件的发生,参数epfd表示epoll实例的文件描述符,参数events表示要监听的事件,参数maxevents表示最多监听多少个事件,参数timeout表示等待时间。
int epoll_wait(int epfd,struct epoll_event *events,int maxevents,int timeout);
epfd:epoll实例的文件描述符events:要监听的事件maxevents:最多监听多少个事件timeout:等待时间0:函数不阻塞,不管epoll实例中有没有就绪的文件描述符,函数被调用后都直接返回大于0:如果epoll实例中没有已就绪的文件描述符,函数阻塞对应的毫秒数再返回-1:函数一直阻塞,直到epoll实例中有已就绪的文件描述符之后才解除阻塞
epoll的使用
这里为实现了一个简单的基于epoll实现的服务端与客户端通讯,大家可以自己测试一下:
//server.cpp
#include <iostream>
#include <unistd.h>
#include <ctype.h>
#include <stdlib.h>
#include <sys/stat.h>
#include <sys/socket.h>
#include <arpa/inet.h>
#include <sys/epoll.h>
#include <string.h>
int main(int argc,char* argv[])
{
if(argc!=3)
{
std::cout<<"命令行参数数量不对"<<std::endl;
std::cout<<"./demo port timeout"<<std::endl;
exit(-1);
}
// 创建套接字
int lfd=socket(AF_INET,SOCK_STREAM,0);
if(lfd<0)
{
perror("create socket");
return -1;
}
//绑定
struct sockaddr_in server_addr;
memset(&server_addr,0,sizeof(server_addr));
server_addr.sin_port=htons(atoi(argv[1]));
server_addr.sin_family=AF_INET;
server_addr.sin_addr.s_addr=htonl(INADDR_ANY);
//设置端口复用
int opt=1;
setsockopt(lfd,SOL_SOCKET,SO_REUSEADDR,&opt,sizeof(opt));
//绑定端口
int ret=bind(lfd,(struct sockaddr*)&server_addr,sizeof(server_addr));
if(ret<0)
{
perror("bind");
exit(-1);
}
//监听
ret=listen(lfd,10);
if(ret<0)
{
perror("listen");
}
//创建epoll实例
int epfd=epoll_create(100);
if(epfd<0)
{
perror("epfd");
exit(-1);
}
struct epoll_event ev;
ev.data.fd=lfd;
ev.events=EPOLLIN;
ret=epoll_ctl(epfd,EPOLL_CTL_ADD,lfd,&ev);
if(ret<0)
{
perror("epoll_ctl");
}
struct epoll_event evs[1024];
int size=(sizeof(evs)/sizeof(struct epoll_event));
while(1)
{
int num=epoll_wait(epfd,evs,size,atoi(argv[2]));
for(int i=0;i<num;i++)
{
int fd=evs[i].data.fd;
if(fd==lfd) //如果是监听的socket
{
int cfd=accept(fd,0,0); //接收客户端的连接
ev.events=EPOLLIN;
ev.data.fd=cfd;
int ret=epoll_ctl(epfd,EPOLL_CTL_ADD,cfd,&ev);
if(ret<0)
{
perror("epoll_ctl");
exit(-1);
}
}
else //不是监听的说明要接收客户端的消息
{
char buffer[1024];
memset(buffer,0,sizeof(buffer));
int len=recv(fd,buffer,sizeof(buffer)-1,0);
std::cout<<len<<std::endl;
if(len==0) //客户端已经断开连接
{
int ret=epoll_ctl(epfd,EPOLL_CTL_DEL,fd,NULL);
if(ret<0)
{
perror("epoll_ctl_del");
exit(-1);
}
close(fd);
}
else if(len>0)
{
std::cout<<333<<std::endl;
std::cout<<"client:"<<buffer<<std::endl;
char* recebuf="ok";
send(fd,recebuf,sizeof(recebuf),0);
}
else
{
perror("recv");
exit(-1);
}
}
}
}
return 0;
}
//client.cpp
#include <iostream>
#include <unistd.h>
#include <ctype.h>
#include <stdlib.h>
#include <sys/socket.h>
#include <arpa/inet.h>
#include <string.h>
int main(int argc, char* argv[])
{
if (argc != 3) {
std::cout << "命令行参数数量不对" << std::endl;
std::cout << "./client server_ip port" << std::endl;
return -1;
}
// 创建套接字
int sockfd = socket(AF_INET, SOCK_STREAM, 0);
if (sockfd < 0) {
perror("socket");
return -1;
}
// 设置服务器地址信息
struct sockaddr_in server_addr;
memset(&server_addr, 0, sizeof(server_addr));
server_addr.sin_family = AF_INET;
server_addr.sin_port = htons(atoi(argv[2]));
if (inet_pton(AF_INET, argv[1], &server_addr.sin_addr) <= 0) {
perror("inet_pton");
close(sockfd);
return -1;
}
// 连接到服务器
if (connect(sockfd, (struct sockaddr*)&server_addr, sizeof(server_addr)) < 0) {
perror("connect");
close(sockfd);
return -1;
}
// 发送数据给服务器
const char* sendbuf = "Hello from client!";
ssize_t send_len = send(sockfd, sendbuf, strlen(sendbuf), 0);
if (send_len < 0) {
perror("send");
close(sockfd);
return -1;
}
std::cout << "Sent: " << sendbuf << std::endl;
// 接收服务器的数据
char buffer[1024];
memset(buffer, 0, sizeof(buffer));
ssize_t recv_len = recv(sockfd, buffer, sizeof(buffer)-1, 0);
if (recv_len > 0) {
std::cout << "Received from server: " << buffer << std::endl;
} else if (recv_len == 0) {
std::cout << "Server closed the connection." << std::endl;
} else {
perror("recv");
}
// 关闭套接字
close(sockfd);
return 0;
}
# makefile
all: client server
server: server.cpp
g++ -g -o server server.cpp
client: client.cpp
g++ -g -o client client.cpp
epoll的工作模式
epoll有两种工作模式:LT(Level Triggered,水平触发)和ET(Edge Triggered,边缘触发)。
LT模式
LT又叫水平模式,是epoll的默认工作模式。在这种模式下,内核会不断地通知你文件描述符是否就绪,即使你已经读取了数据。也就是说,即使你读取了数据,文件描述符仍然被认为是就绪的,内核会继续通知你。这种模式适用于需要不断地检查文件描述符是否就绪的场景。
水平模式主要有以下特点:
- 这是epoll的默认工作模式。
- 在LT模式下,当一个文件描述符准备好进行读写操作时,epoll会通知应用程序。
- 如果应用程序没有立即处理该事件,或者在处理过程中没有完全读取或写入所有数据,那么只要文件描述符仍然处于就绪状态,epoll将继续通知应用程序。
其实对于大多数应用来说,LT模式足够使用,并且它的行为与传统的poll和select相似
ET模式
ET又叫边缘模式,是epoll的高级模式。在这种模式下,内核只会通知你文件描述符从非就绪状态变为就绪状态一次,即使你读取了数据,文件描述符仍然被认为是非就绪的,内核不会继续通知你。这种模式适用于需要高效处理大量并发连接的场景。
边缘模式主要有以下特点:
- ET模式是一种低延迟、高性能的工作模式。
- 在ET模式下,epoll只会在状态发生变化时通知应用程序一次。例如,如果一个文件描述符从非就绪变为就绪,epoll将通知应用程序;但是,如果应用程序未能在第一次通知后立即处理完所有可用的数据,那么即使该文件描述符仍然是就绪状态,epoll也不会再次发送通知,直到该文件描述符的状态再次发生变化(即从就绪变回非就绪,再由非就绪变成就绪)。
因此,在ET模式下,应用程序必须确保每次收到通知时都尽可能多地读取或写入数据,以避免错过后续的通知。这通常意味着在循环中尽可能多地尝试读写操作,直到遇到EAGAIN或EWOULDBLOCK错误为止,这表明当前没有更多可读写的就绪数据。
PS:
- LT模式会不断通知应用程序,即使应用程序已经开始读取数据,这样可以保证应用程序能够及时处理数据,但是 频繁的通知会带来性能的损耗,而ET模式只会在状态发生变化时通知应用程序一次,因此应用程序需要确保每次收到通知时都尽可能多地读取或写入数据,以避免错过后续的通知。所以ET模式要求应用程序在每次收到通知时都尽可能多地读取或写入数据,否则可能会错过后续的通知。因此,ET模式通常需要更复杂的编程逻辑,并且对应用程序的设计和实现有更高的要求。
2.我们在使用ET模式要设置EPOLLET标志如下:
if(fd==lfd) //如果是监听的socket
{
int cfd=accept(fd,0,0); //接收客户端的连接
ev.events=EPOLLIN|EPOLLET; //设置边沿触发
ev.data.fd=cfd;
int ret=epoll_ctl(epfd,EPOLL_CTL_ADD,cfd,&ev);
if(ret<0)
{
perror("epoll_ctl");
exit(-1);
}
}
3.LT模式下支持阻塞和非阻塞,而ET模式下只支持非阻塞。